Xiaofan Li (Shalfun Li)I obtained my Bachelor's degree from Zhejiang University (ZJU), where I conducted research under the supervision of Professors Kaiwei Wang, Guofeng Zhang, and Zhihai Xu. During my undergraduate studies, I started at SenseTime, working on computer vision with an emphasis on 2D/3D optical flow prediction. Then, I joined the Joint Algorithm Department of Rockchip & ZJU, focusing on low-level vision and face-related algorithms, and led the open-sourcing of RKNN (⭐ ~3k). At Baidu, I worked in the Autonomous Driving Foundation Model Department (ADFM), where I oversaw the world model and concurrently served as head of ADFM research, with work spanning 3D scene understanding, vision-language models, implicit rendering, 4D generation, and world models. I am currently with X Square Robot, leading the research of the world unified model, where I continue exploring the intersection of generative models, large language models, and embodied intelligence. Please feel free to reach out if you're interested in joining.
[Email]
[Github]
[Google Scholar]
[Linkedin] |

|
News (Recent 2 years)
 Wan2.1 as a contribution to Wan2.1 Community Works.
Wan2.1, within one week of the Wan2.1 release. Wan2.1 as a contribution to Wan2.1 Community Works.
Wan2.1, within one week of the Wan2.1 release.
|
Publications |

|
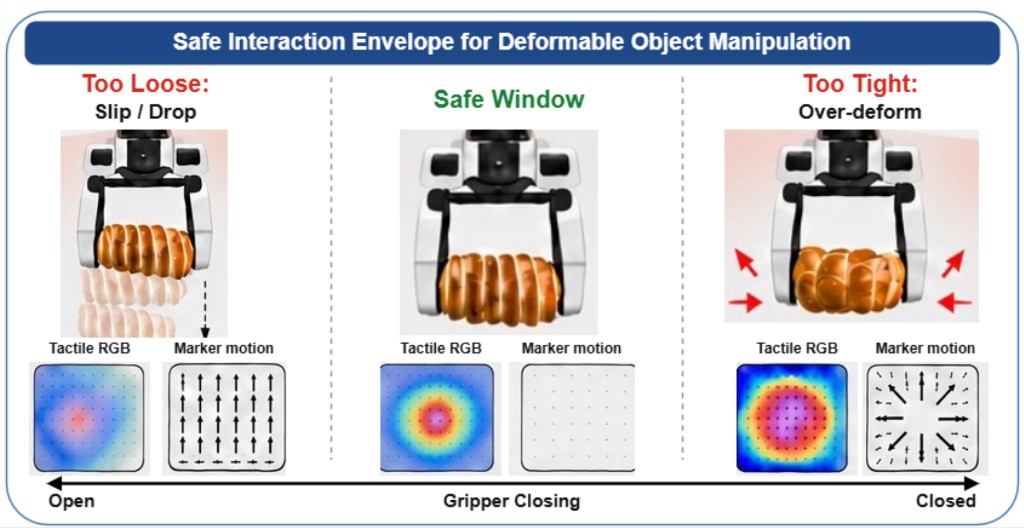
Tianxing Chen*§, Yue Chen*§†, Zixuan Li*, Junyuan Tang*, Kailun Su*, Weijie Wan*, Baijun Chen*, Haoran Lu, Haowen Yan, Honghao Su, Zhiyang Dou, Kaixuan Wang, Dandan Zhang, Yunze Liu, Yan Qin, Qiwei Liang, Qiwei Wu, Zijian Lin, Wenwei Lin, Yuran Wang, Minghua He, Tianshu Wu, Ruihai Wu, Jingquan Zhou, Kai-Chong Lei, Haibao Yu, Yuanfeng Ji, Weiyang Jin, Guanyu Lin, Xiaofan Li, Qi Xiong, Renjing Xu, Zhongyu Li, Wenhao Chai, Enze Xie, Ziwei Wang, Yao Mu, Hao Dong, Wojciech Matusik, Mingyu Ding†, Wenbo Ding†, Ping Luo†, Masayoshi Tomizuka† (* co-first authors, § co-project leaders, † corresponding authors) arXiv preprint arXiv:2607.04434, 2026 [paper] [benchmark code] [XPolicyLab code] [project page] [leaderboard] |
|
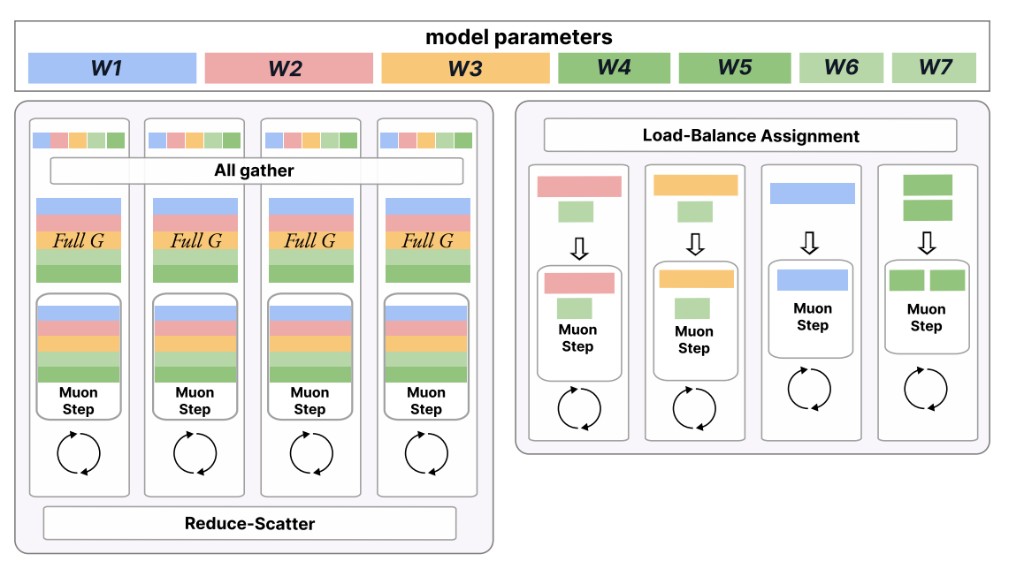
Bowen Jing*, Mingxin Wang*, Ruiyang Hao, Chenchen Ge, Hanwen Shen, Junjie He, Yang Cui, Yiming Hou, Weitao Zhou†, Jiawei Wang, Minglei Li, Dandan Zhang, Ding Zhao, Houde Liu, Xiaofan Li, Si Liu, Ping Luo, Haibao Yu† (* equal contribution, † corresponding author) arXiv preprint arXiv:2607.04234, 2026 [paper] [code] [project page] |
|
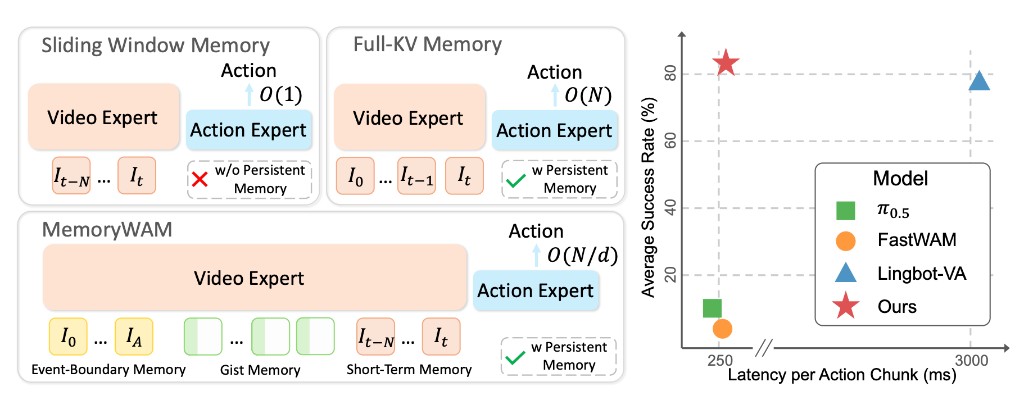
Vincent Chen*, Starrick Liu*, Regis Cheng*, Dance Yang*, Shalfun Li*, Ryan Yu, Lucy Liang, Hang Su, Roy Gan, Hao Wang, Qian Wang (* equal contribution) arXiv preprint arXiv:2606.27153, 2026 [paper] [code] |
|
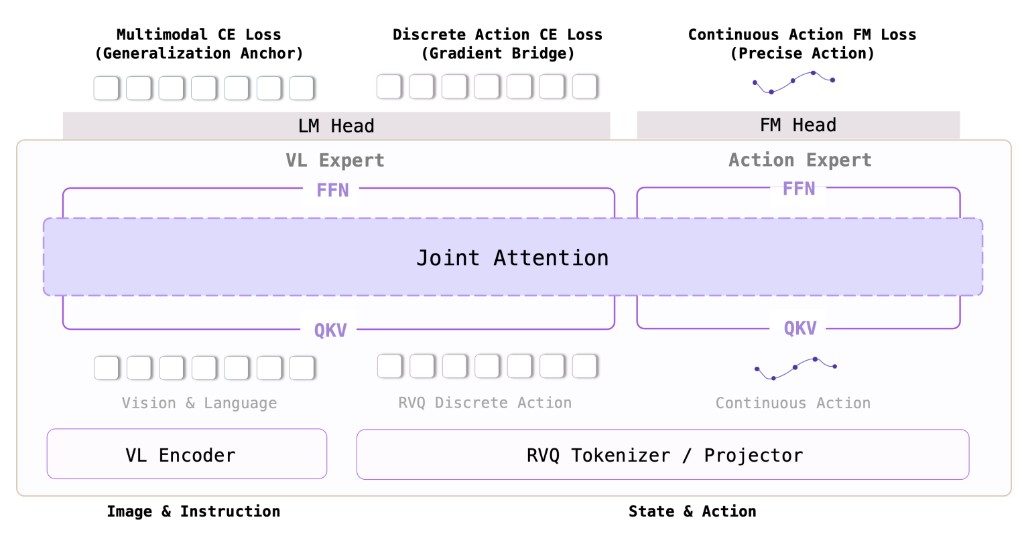
Sizhe Yang*, Juncheng Mu*, Tianming Wei, Chenhao Lu, Xiaofan Li, Linning Xu, Zhengrong Xue, Zhecheng Yuan, Dahua Lin, Jiangmiao Pang, Huazhe Xu (* equal contribution) arXiv preprint arXiv:2606.20562, 2026 [paper] [project page] |
|
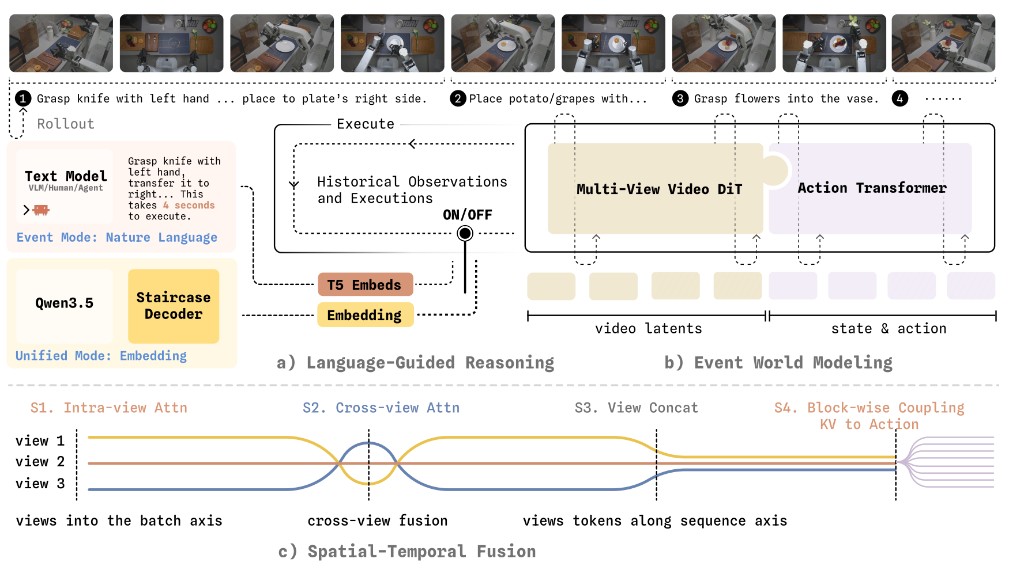
Ryan Yu*, Pushi Zhang*, Starrick Liu*, Brae Liu*, Miracle Kang*, Shalfun Li*, Lights Shi, Ellie Ma, Ping Yang, Chris Pan, Jerry Chen, Dongxiu Liu, Rain Sun, Miles Guo, Byron Zhang, Hugo Zhou, Zach Xu, Vincent Chen, Harrison Huang, James Wang, Dance Kuzi, Andy Zhai, Hang Su, Roy Gan, Lucy Liang, Hao Wang, Qian Wang (* equal contribution) arXiv preprint arXiv:2605.30877, 2026 [paper] [code] [project page] |
|
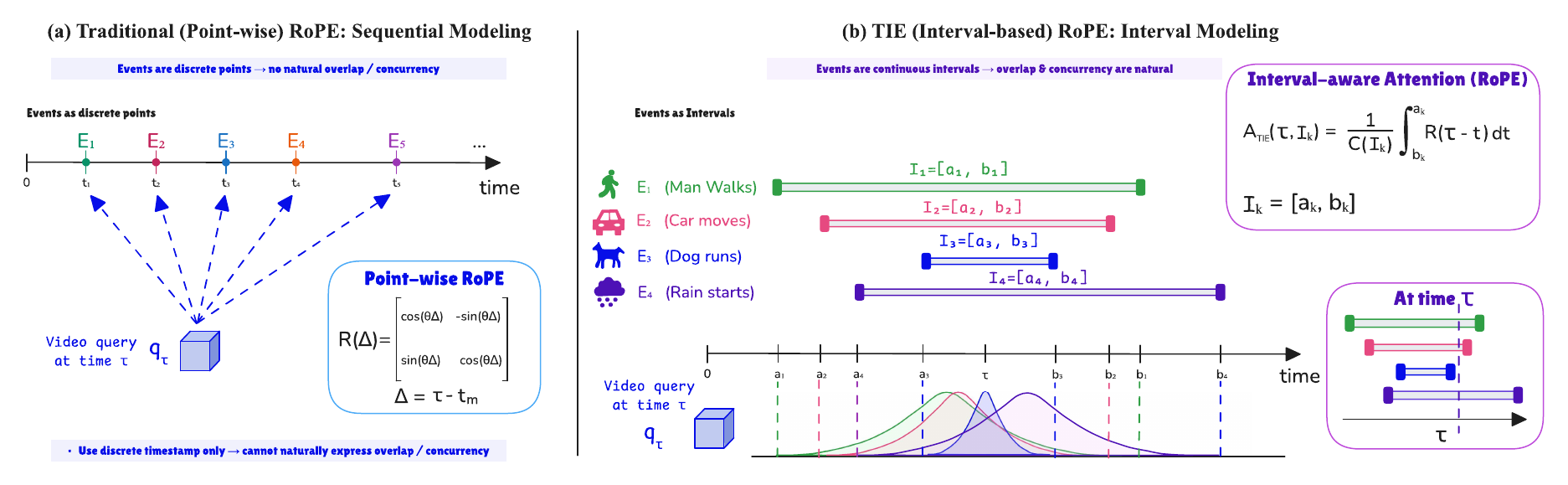
Shalfun Li*†, Victor Yao*, Charles Yang*, Truth Qu*, Regis Cheng*, Ryan Yu*, Howard Lu*, Newton Von*, Vincent Chen*, Yohann Tang, Maeve Zhang, Ellie Ma, Gody Li, Sage Yang, Lorien Shu, J.W. Gao, Ethan Chen, Colin Ye, Yu Sun, Elise Mon, PS Zhang, Neo Li, Lily Li, James Wang, Ping Yang, Chris Pan, Lucy Liang, Hang Su, Roy Gan, Hao Wang, Qian Wang (* equal contribution, † Project Lead) arXiv preprint arXiv:2606.01955, 2026 [paper] [code] [X] |
|
Zhilei Shu*, Shangwen Zhu*, Zihang Liang, Xiaofan Li, Qianyu Peng, Xinyu Cui, Bo Ye, Yiming Li, Fan Cheng, Jian Zhao, Yang Cao, Zheng-Jun Zha†, Ruili Feng arXiv preprint arXiv:2605.10543, 2026 [paper] [project page] |

|
Zijian Zhang, Yuqing Jiang, Qian Cheng, Xiaofan Li, Si Liu, Ding Zhao, Ping Luo, Weitao Zhou, Haibao Yu arXiv preprint arXiv:2605.20752, 2026 [paper] [code] |

|
James Wang, Primo Pu, Zephyr Fung, Alex Wang, Sam Wang, Bender Deng, Kevin Wang, Zivid Liu, Chris Pan, Panda Yang, Andy Zhai, Lucy Liang, Shalfun Li, Johnny Sun, Jacky Xu, Will Tian, Kai Yan, Kohler Ye, Scott Li, Qian Wang, Roy Gan, Hao Wang arXiv preprint arXiv:2604.13001, 2026 [paper] [code] |

|
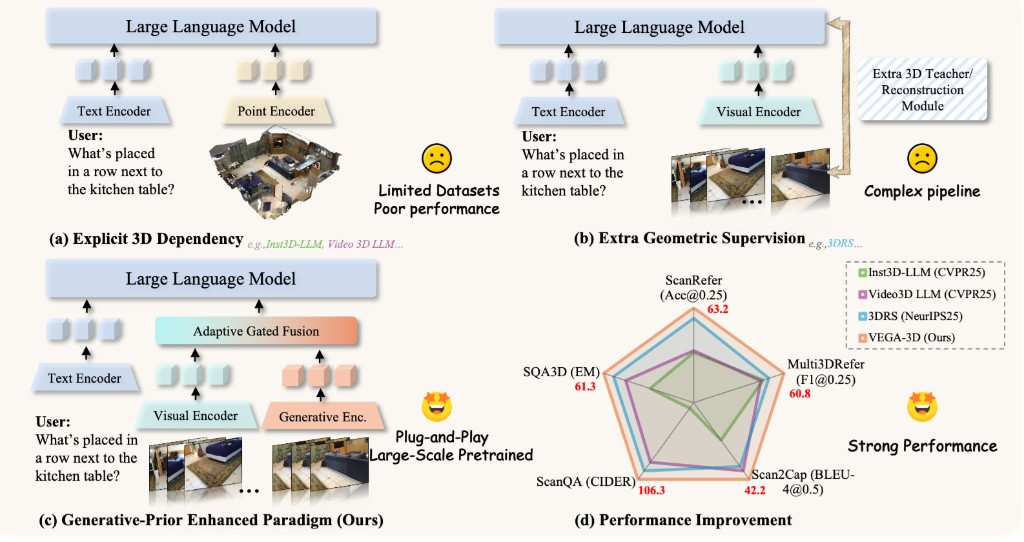
Yu Sun, Meng Cao, Yang Ping, Kaidong Zhang, Qingxuan Chen, Rongtao Xu, Liangwang Ruan, Xuecheng Chen, Dongxiu Liu, Yunxiao Yan, Zunnan Xu, Runze Xu, Charles Yang, Peilun Zhang, Xiaofan Li, Ruyi Gan, Liang Ma, Yuehao Yin, Jincheng Yu, Lufang Chen, Yuxin Liang, Peng Zhai, Hao Wang, Ivan Laptev, Ian Reid, Qian Wang, Xiaodan Liang arXiv preprint arXiv:2603.28545, 2026 [paper] [code] |
|
Xianjin Wu, Dingkang Liang, Tianrui Feng, Kui Xia, Yumeng Zhang, Xiaofan Li, Xiao Tan, Xiang Bai arXiv preprint arXiv:2603.19235, 2026 [paper] [code] |

|
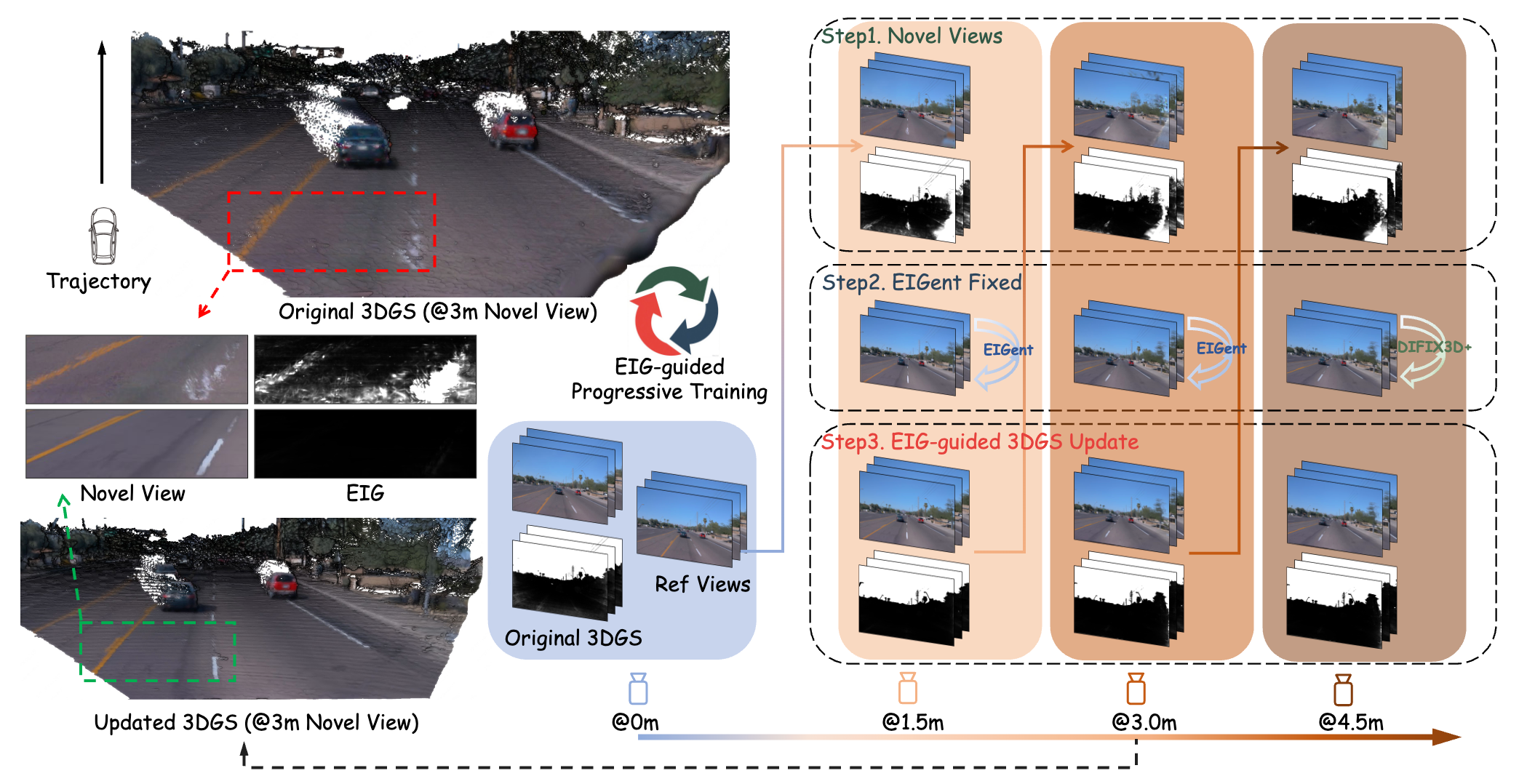
Xiaofan Li*, Chenming Wu*, Yanpeng Sun, Jiaming Zhou, Delin Qu, Yansong Qu, Weihao Bo, Haibao Yu, Dingkang Liang Computer Vision and Pattern Recognition Conference (CVPR), 2026 [paper] [project page] |
|
YuAn Wang*, Xiaofan Li*†, Chi Huang, Wenhao Zhang, Hao Li, Bosheng Wang, Xun Sun, Jun Wang (* equal contribution, † Corresponding author) Computer Vision and Pattern Recognition Conference (CVPR), 2026 [paper] [code] [project page] |
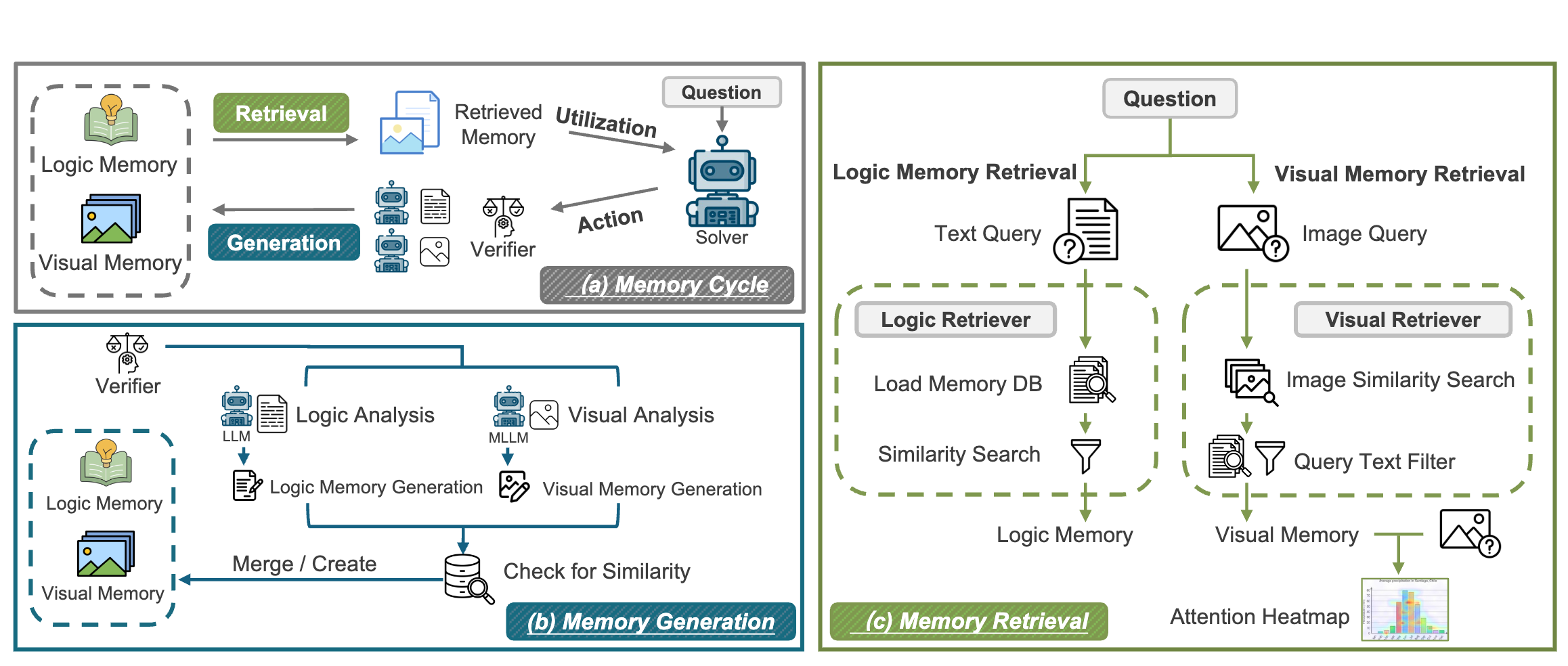
|
Weihao Bo, Shan Zhang, Yanpeng Sun, Jingjing Wu, Qunyi Xie, Xiao Tan, Kunbin Chen, Wei He, Xiaofan Li, Na Zhao, Jingdong Wang, Zechao Li Computer Vision and Pattern Recognition Conference (CVPR), 2026 [paper] [code] [project page] |

|
Yanpeng Sun, Jing Hao, Ke Zhu, Jiang-Jiang Liu, Yuxiang Zhao, Xiaofan Li, Gang Zhang, Zechao Li, Jingdong Wang Computer Vision and Pattern Recognition Conference (CVPR), 2026 [paper] |
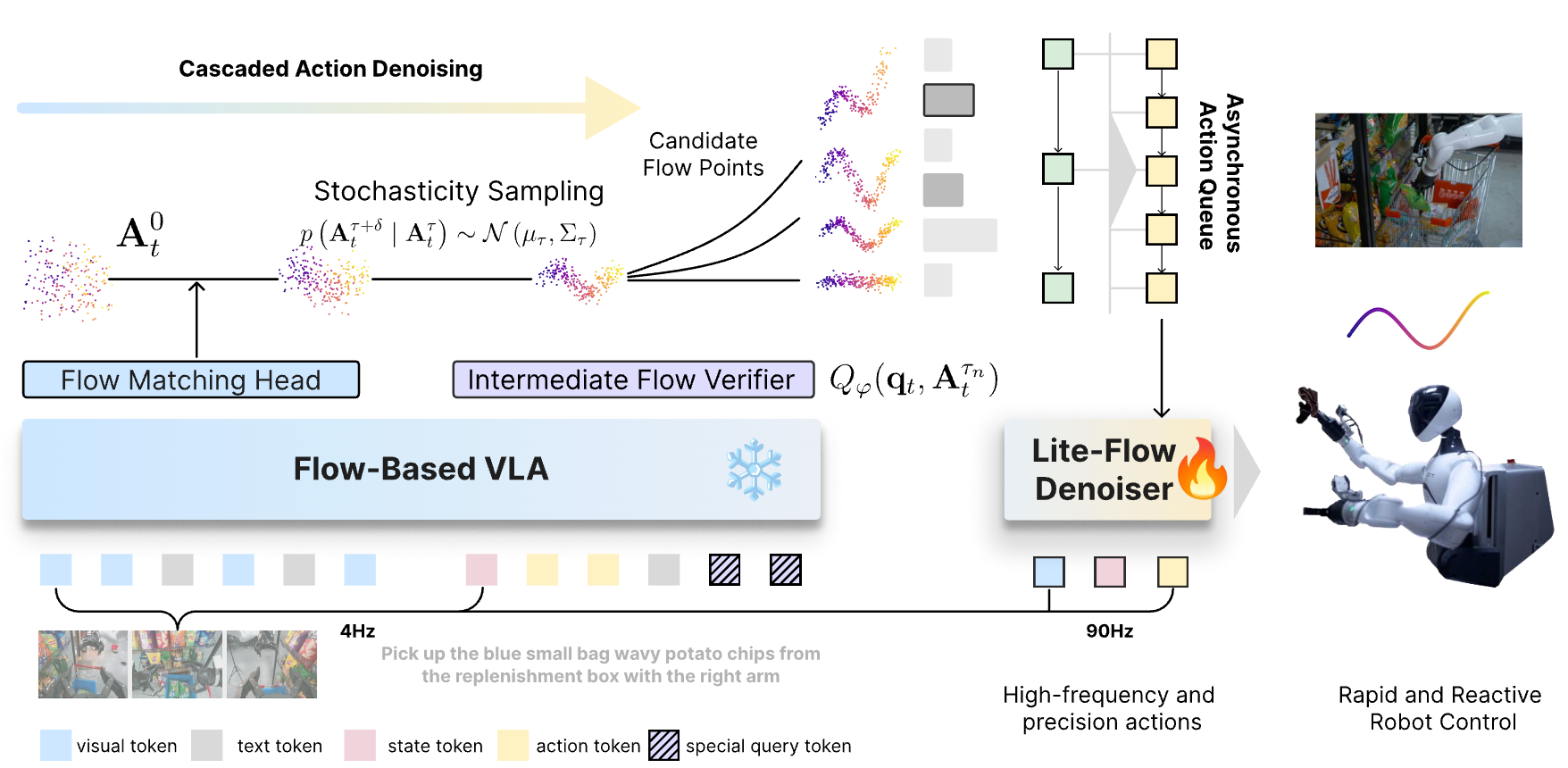
|
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Jiarui Li, Qi Lv, Yiwen Tang, Li Kang, Heng Zhou, Xianqiang Gao, Yuhang Tang, Xiaofan Li, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, Dong Wang, Xuelong Li Computer Vision and Pattern Recognition Conference (CVPR), 2026 |
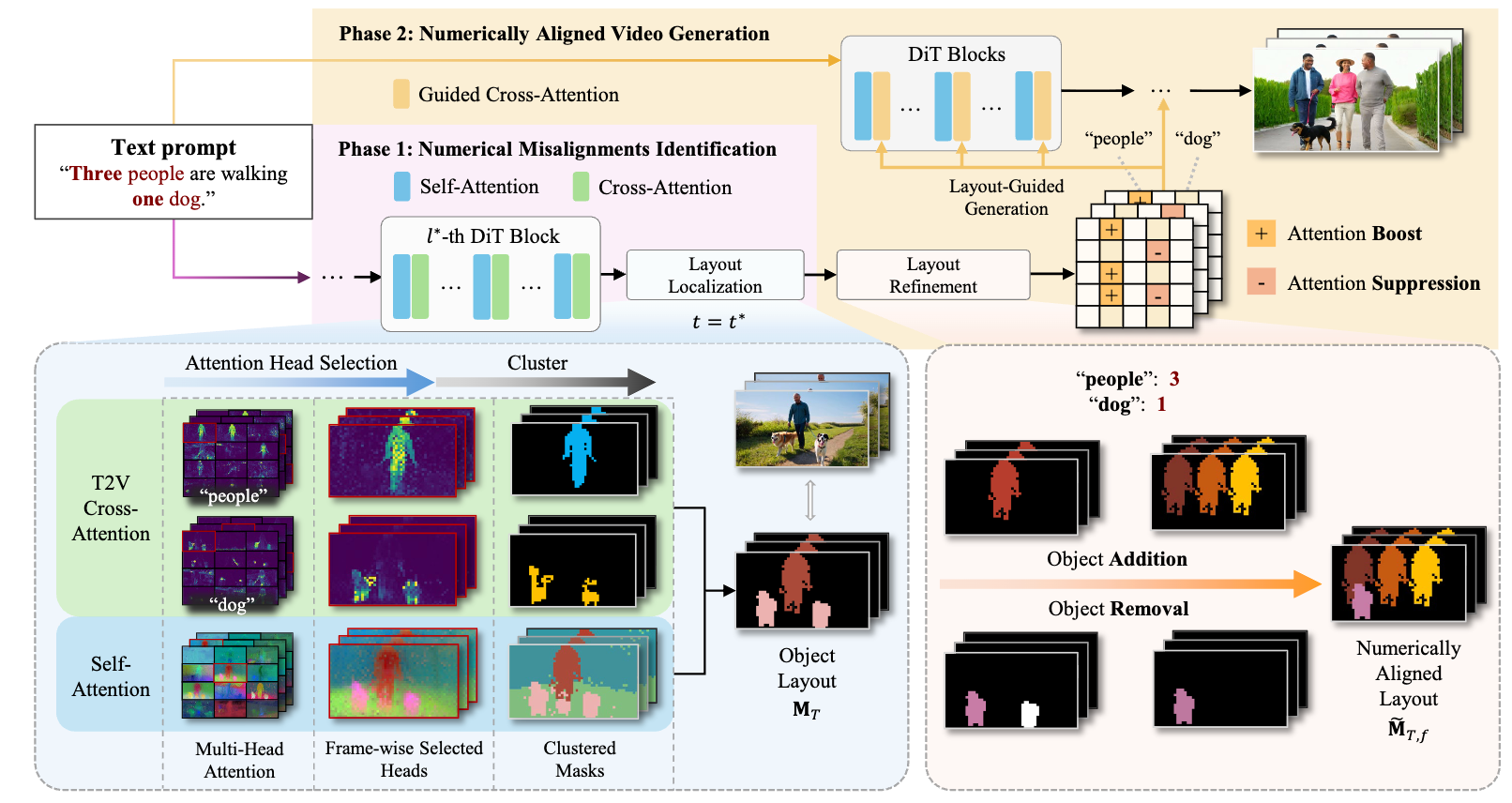
|
Zhengyang Sun, Yu Chen, Xin Zhou, Xiaofan Li, Xiwu Chen, Dingkang Liang, Xiang Bai Computer Vision and Pattern Recognition Conference (CVPR), 2026 [paper] [code] |
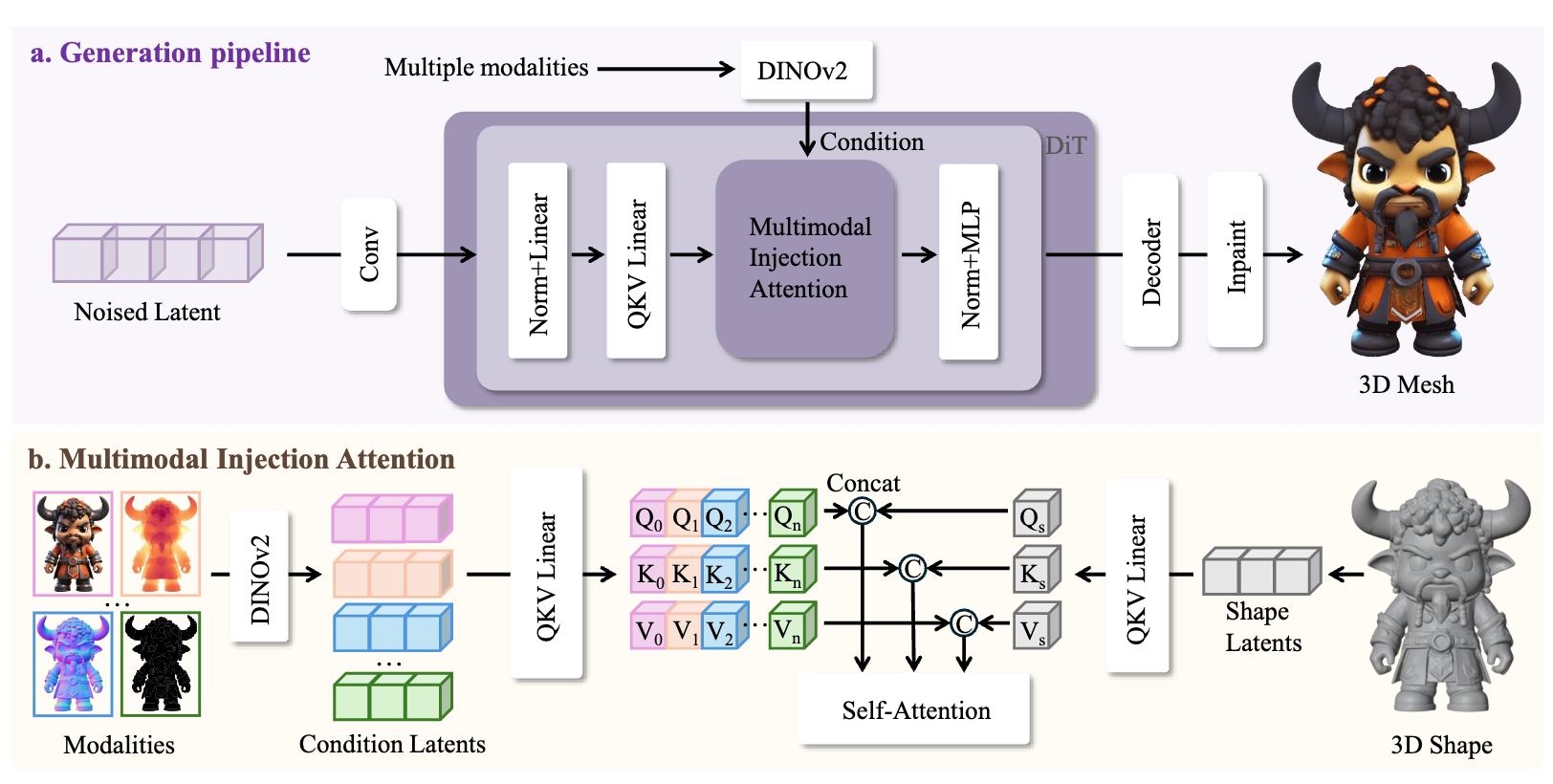
|
Mingyang Du, Dingkang Liang, Xin Zhou, Yumeng Zhang, Xiaofan Li, Kui Xia, Xiao Tan, Xiang Bai Computer Vision and Pattern Recognition Conference (CVPR), 2026 |
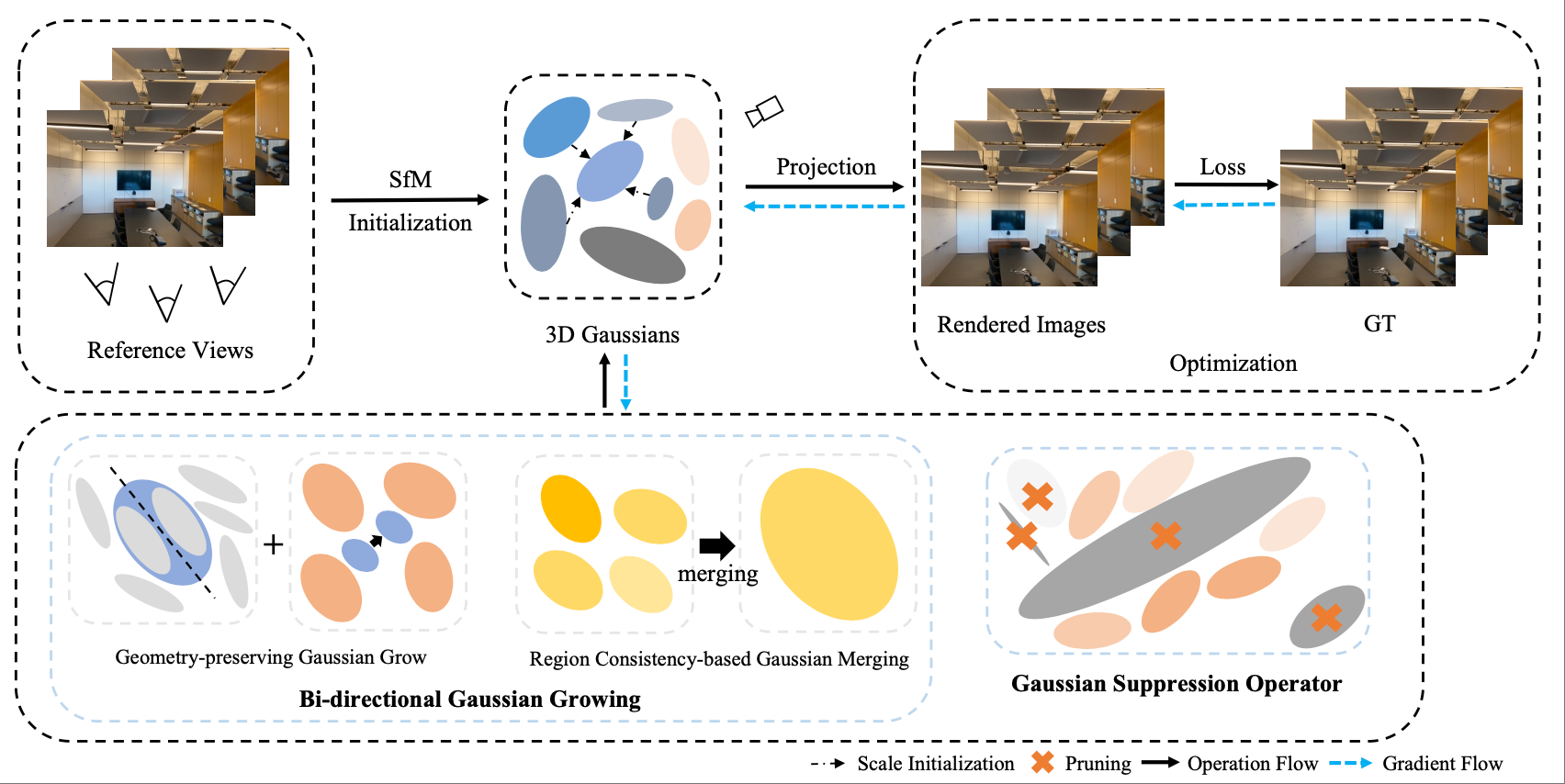
|
Fan Duan, Yumeng Zhang, Xiaofan Li, Xiao Tan, Li Chen IEEE Transactions on Multimedia (TMM), 2026 [paper] |
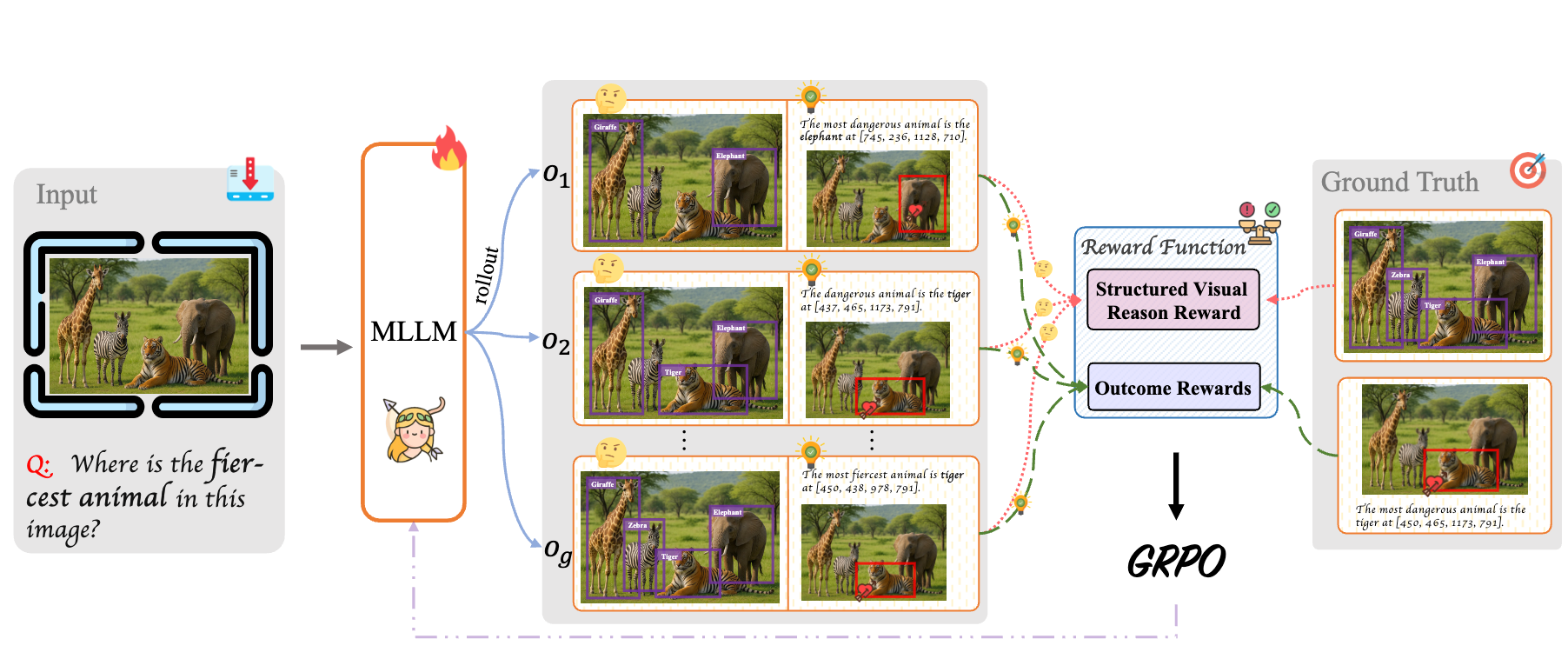
|
Wei Tang, Yanpeng Sun, Shan Zhang, Xiaofan Li†, Piotr Koniusz, Wei Li, Na Zhao, Zechao Li († Corresponding author) International Conference on Machine Learning (ICML), 2026 [paper] [code] [project page] |

|
Weihao Bo, Jingwen Qin, Yanpeng Sun, Fei Shen, Xiaofan Li, Zechao Li International Conference on Machine Learning (ICML), 2026 |
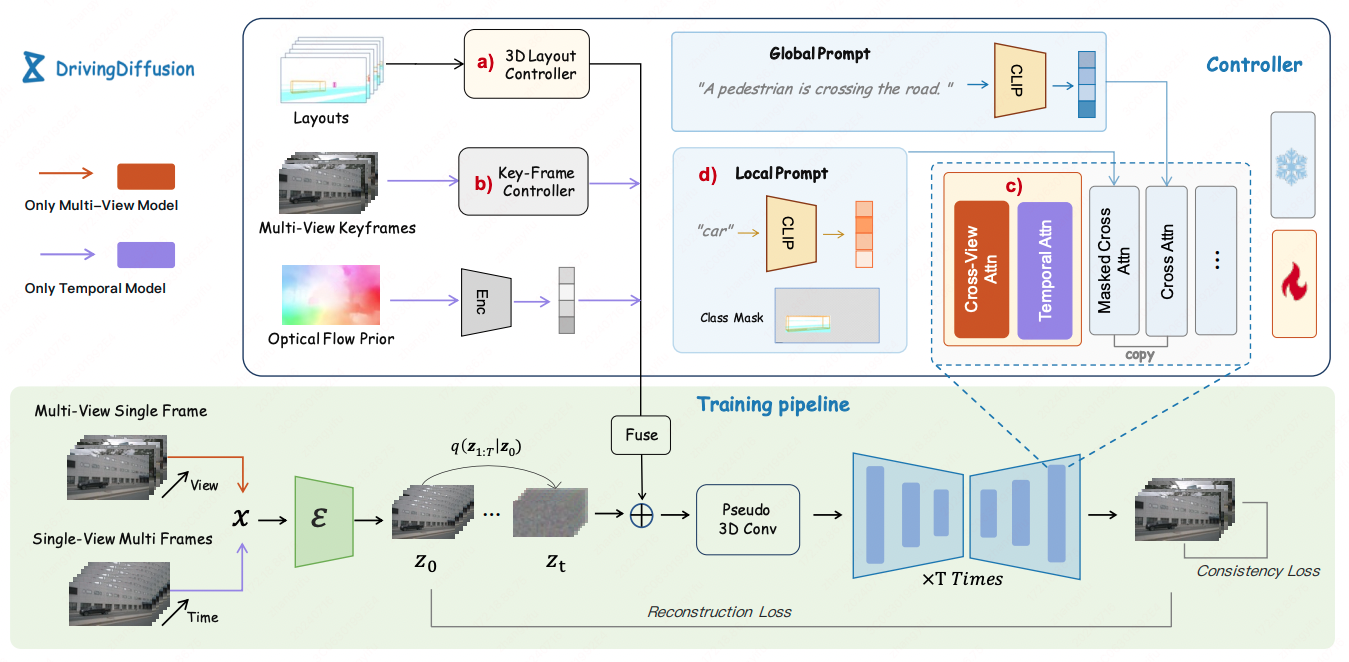
|
Xiaofan Li, Yifu Zhang, Xiaoqing Ye European Conference on Computer Vision (ECCV), 2024 [paper] [code(⭐ 500+)] |
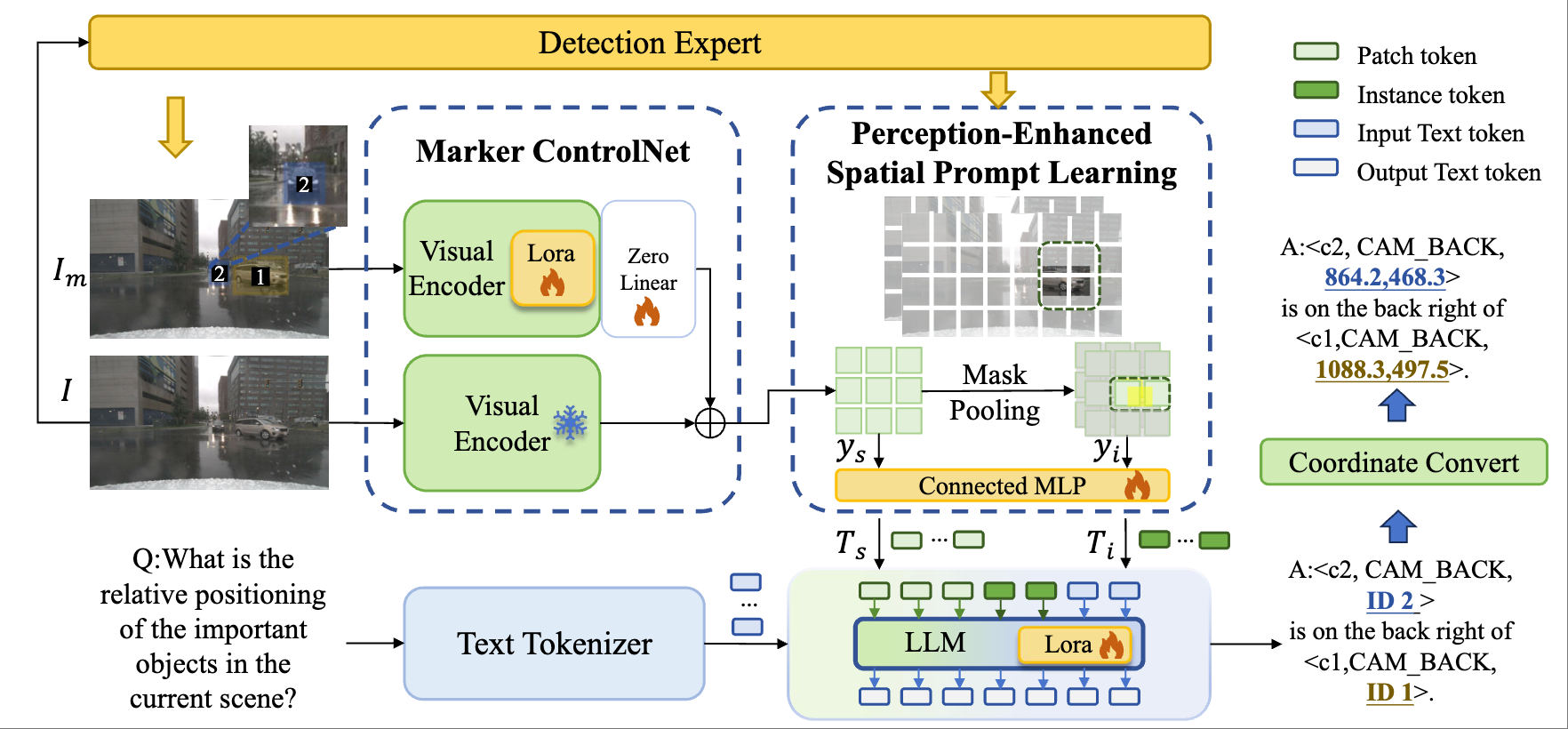
|
Zhiyuan Zhang*, Xiaofan Li*, Zhihao Xu, Wenjie Peng, Zijian Zhou, Miaojing Shi, Shuangping Huang (* equal contribution) Computer Vision and Pattern Recognition Conference (CVPR), 2025 [Highlight] [paper] |
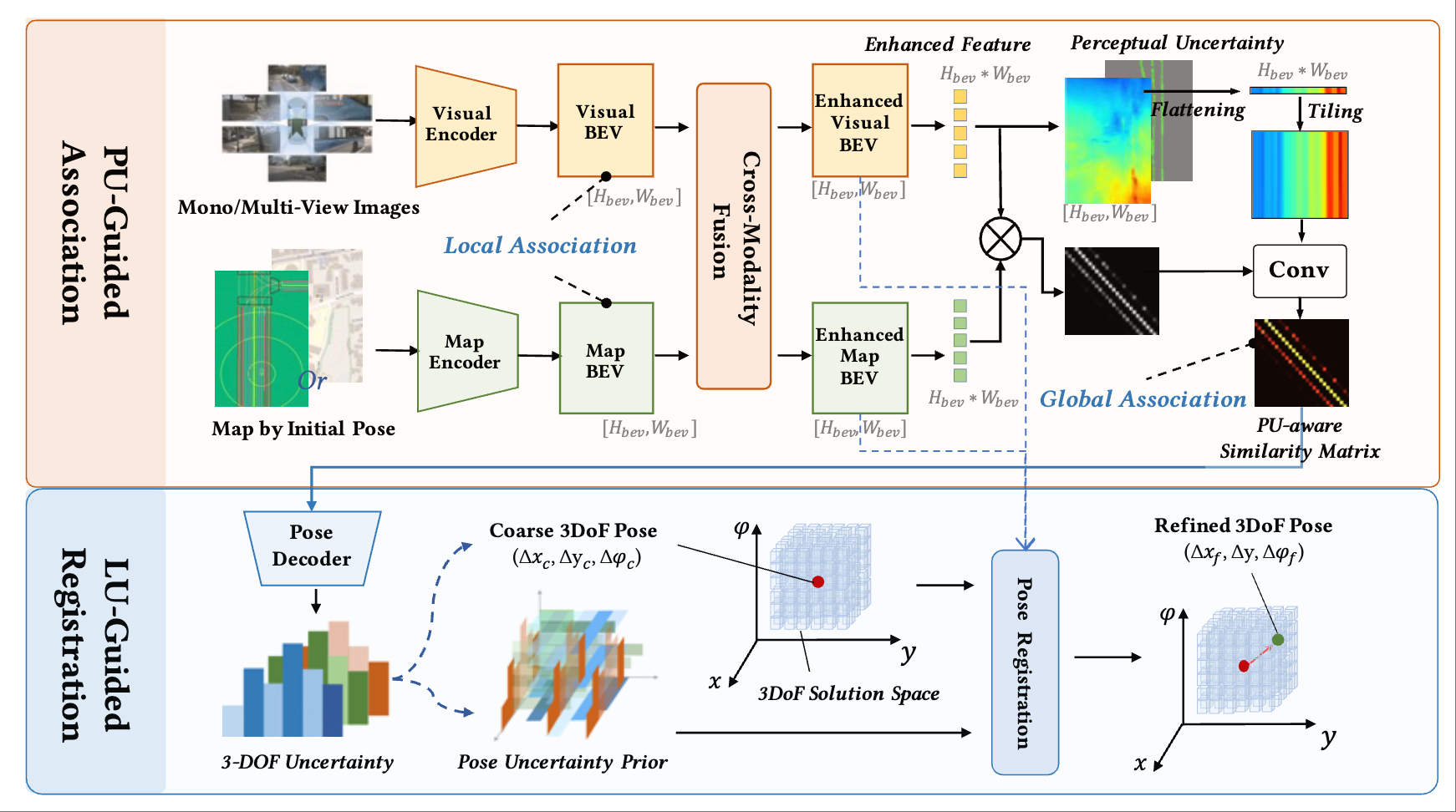
|
Xiaofan Li, Zhihao Xu, Chenming Wu, Zhao Yang, Yumeng Zhang, Jiang-Jiang Liu, Haibao Yu, Xiaoqing Ye, YuAn Wang, Shirui Li, Xun Sun, Ji Wan, Jun Wang International Conference on Computer Vision (ICCV), 2025 [paper] |

|
Yansong Qu, Dian Chen, Xinyang Li, Xiaofan Li†, Shengchuan Zhang, Liujuan Cao, Rongrong Ji† († equal advising) ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques (SIGGRAPH), 2025 [paper] [code] |
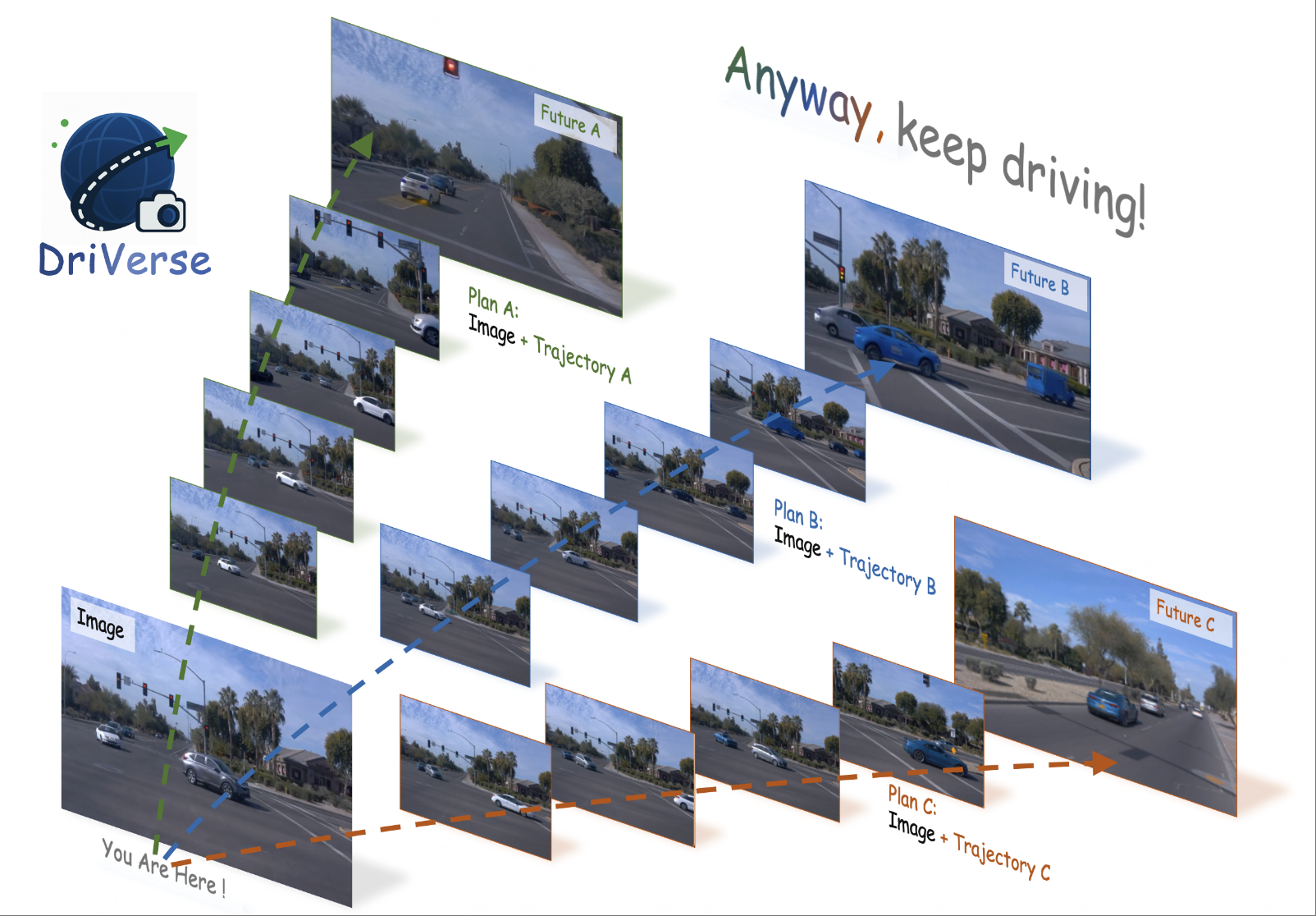
|
Xiaofan Li, Chenming Wu, Zhao Yang, Zhihao Xu, Dingkang Liang, Yumeng Zhang, Ji Wan, Jun Wang ACM International Conference on Multimedia (ACM MM), 2025 [paper] [code(⭐ 200+)] |
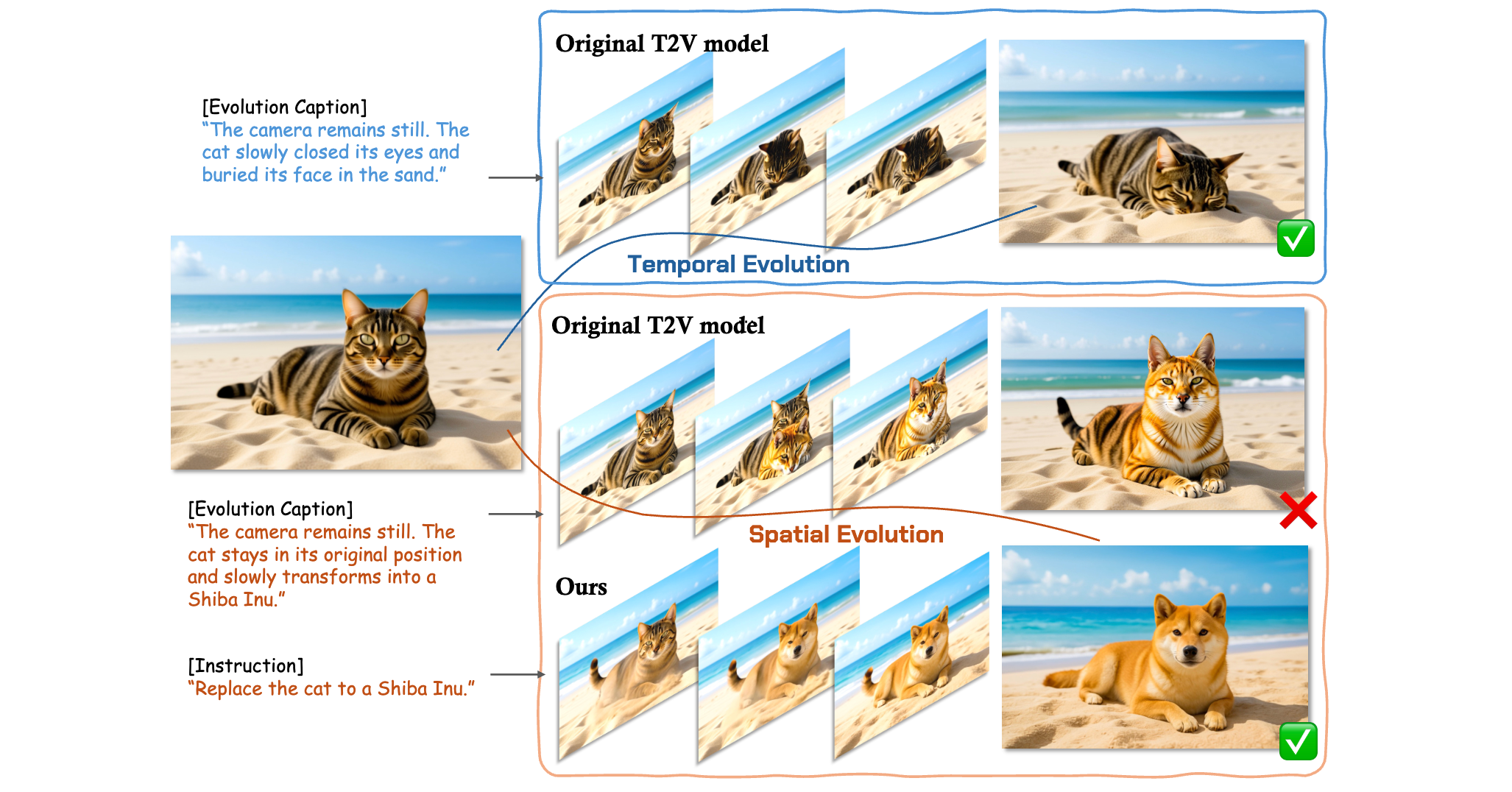
|
Xiaofan Li, Yanpeng Sun, Chenming Wu, Fan Duan, YuAn Wang, Weihao Bo, Yumeng Zhang, Dingkang Liang IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026 [paper] [project page] |
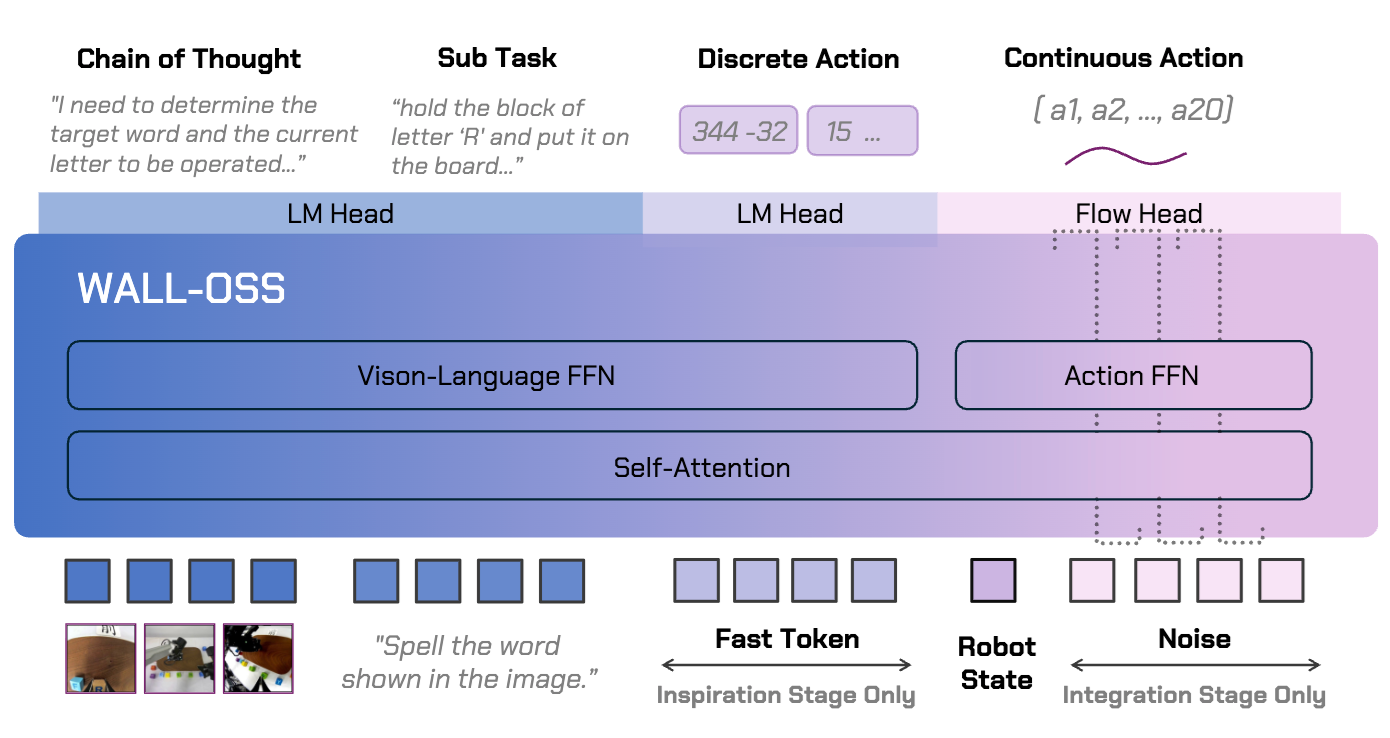
|
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang, Hugo Zhou, James Wang, Lights Shi, Lucy Liang, Make Wang, Qian Wang, Roy Gan, Ryan Yu, Shalfun Li, Starrick Liu, Sylas Chen, Vincent Chen, Zach Xu arXiv preprint arXiv:2509.11766, 2025 [paper] [code(⭐ 800+)] |

|
Chenming Wu*, Xiaofan Li*, Chengkai Dai (* equal contribution) IEEE Robotics and Automation Letters (RAL), 2025 [paper] |
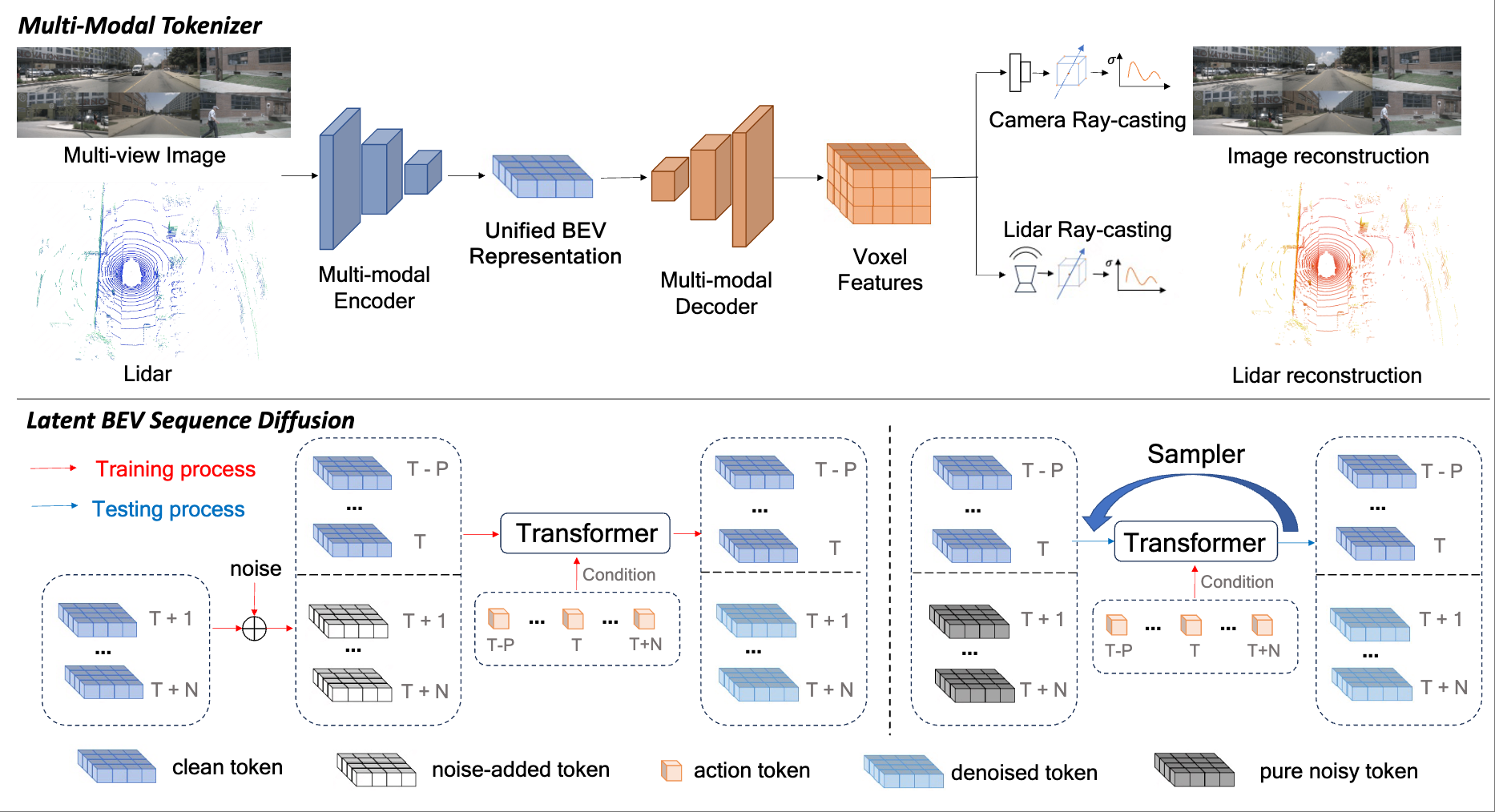
|
Yumeng Zhang*, Shi Gong*, Kaixin Xiong*, Xiaoqing Ye, Xiaofan Li, Xiao Tan, Fan Wang, Jizhou Huang, Hua Wu, Haifeng Wang arXiv preprint arXiv:2407.05679, 2024 [paper] [code] |
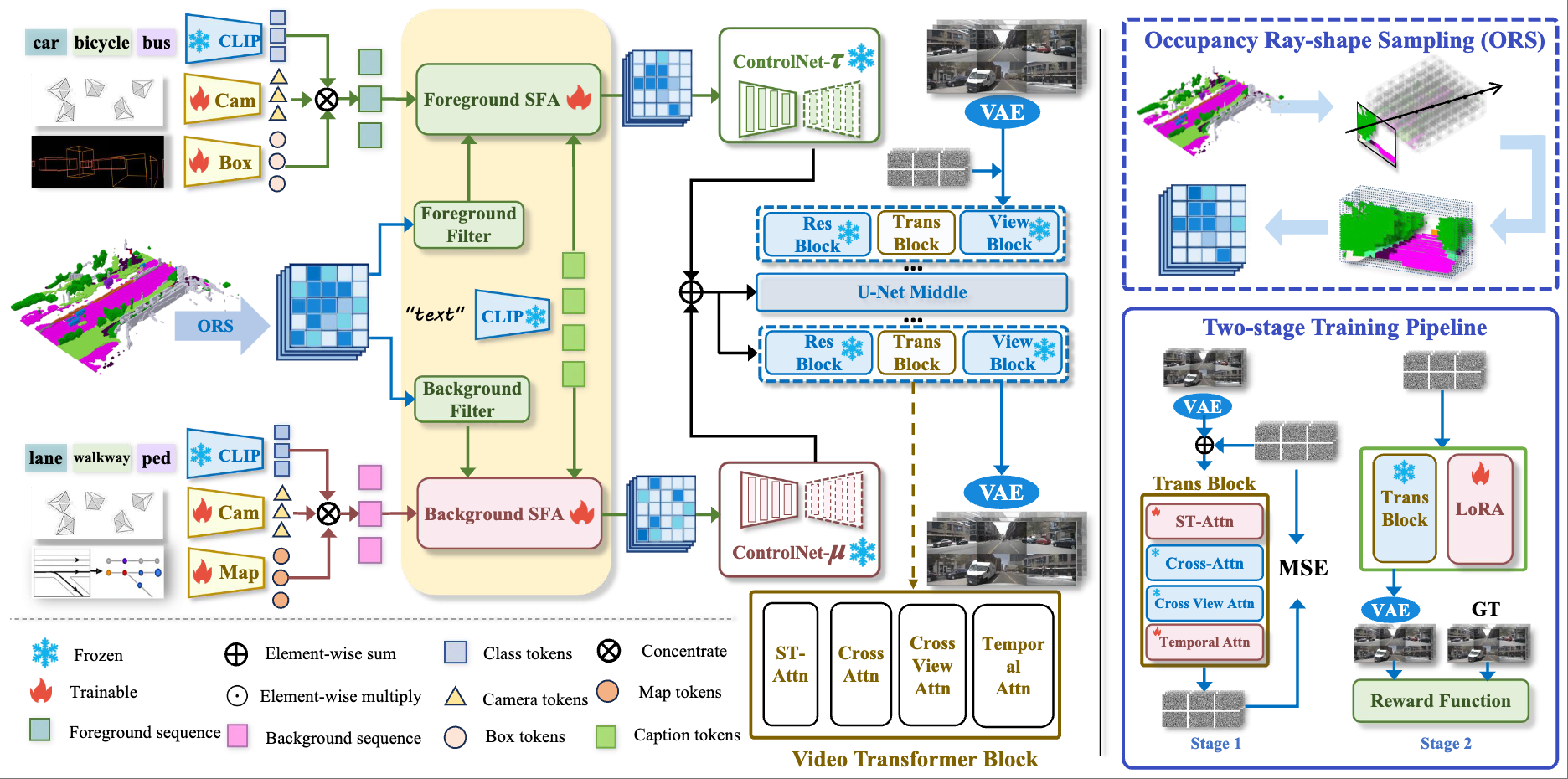
|
Zhao Yang, Zezhong Qian, Xiaofan Li†, Weixiang Xu, Gongpeng Zhao, Ruohong Yu, Lingsi Zhu, Longjun Liu† († equal advising) IEEE International Conference on Robotics and Automation (ICRA), 2025 [paper] [code] |
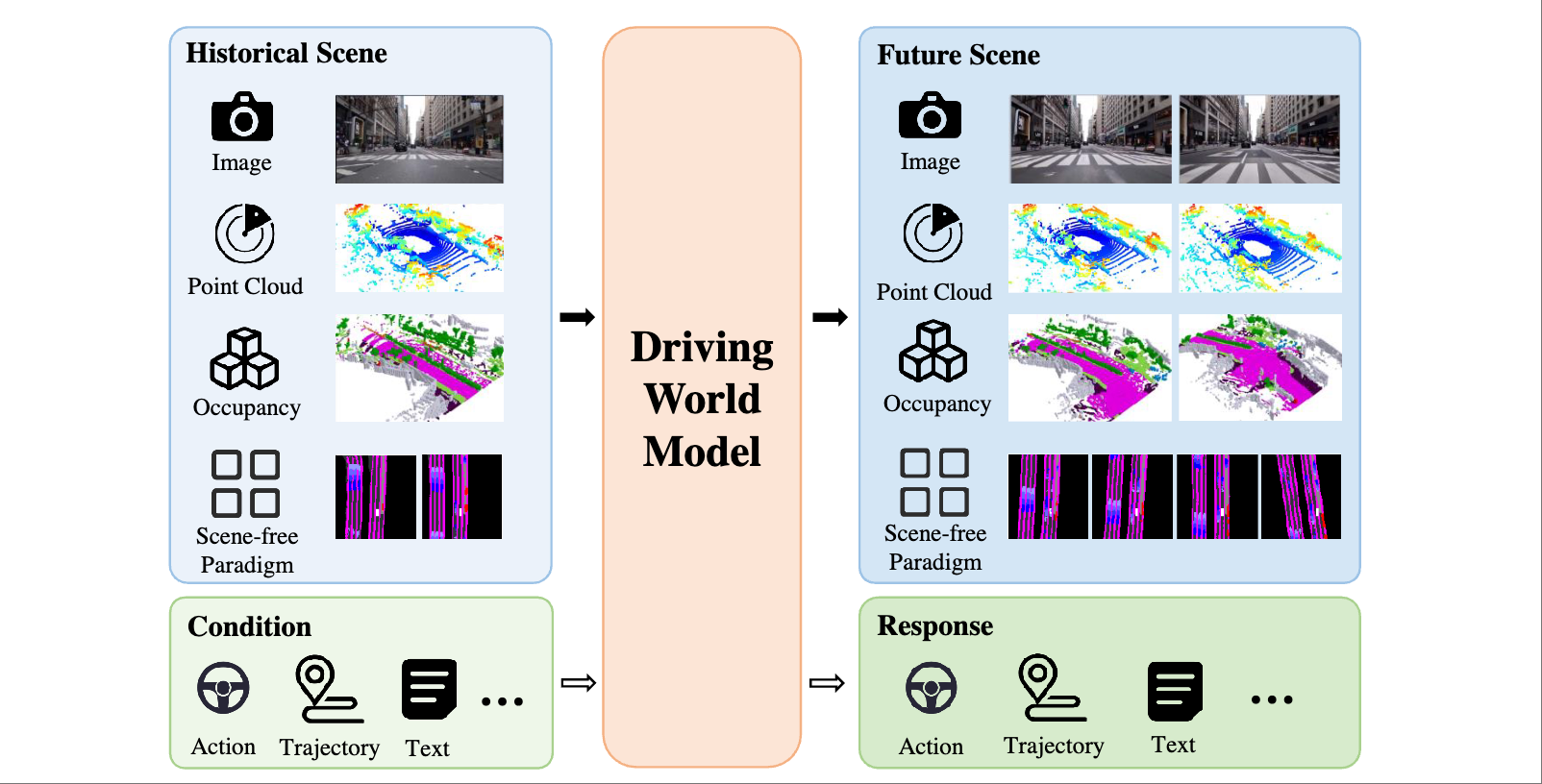
|
Sifan Tu, Xin Zhou, Dingkang Liang, Xingyu Jiang, Yumeng Zhang, Xiaofan Li†, Xiang Bai† († equal advising) International Joint Conference on Artificial Intelligence (IJCAI), 2024 [paper] [code(⭐ ~2k)] |
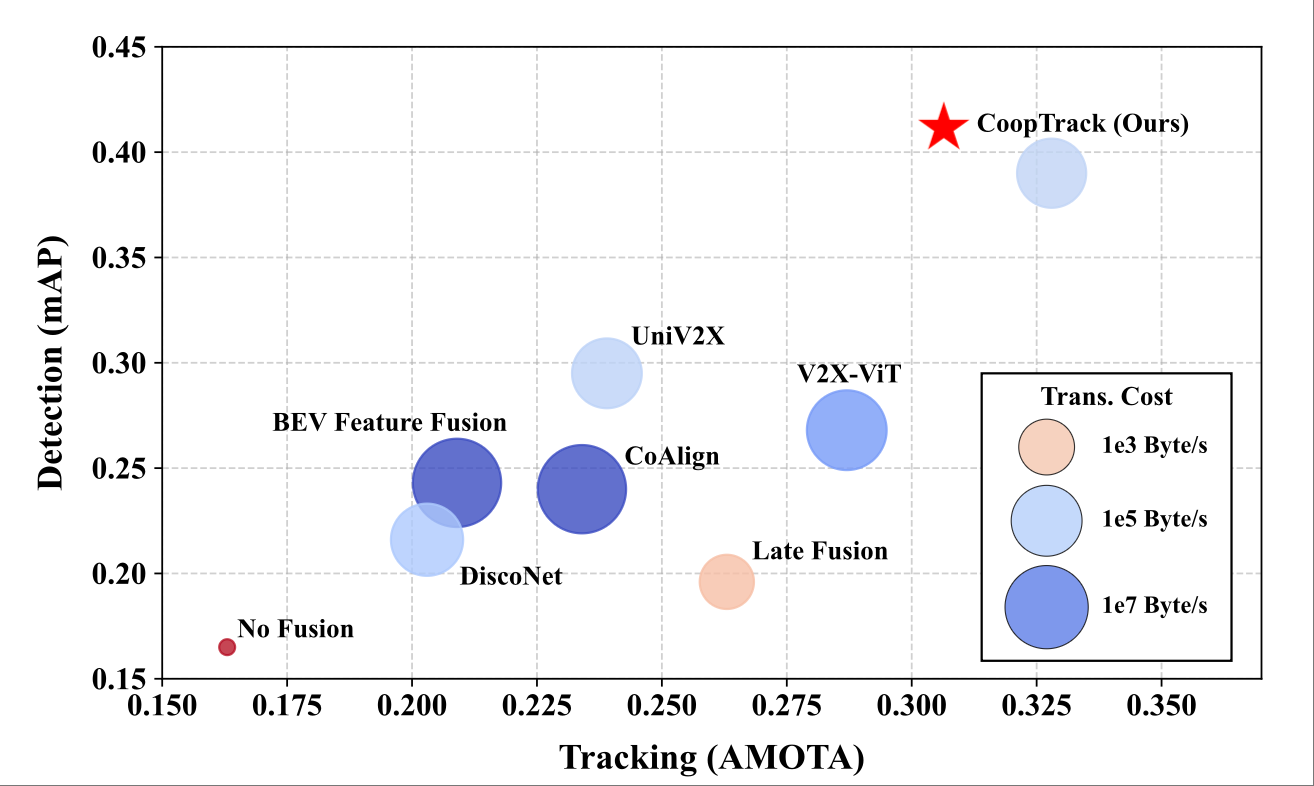
|
Jiaru Zhong, Jiahao Wang, Jiahui Xu, Xiaofan Li, Zaiqing Nie, Haibao Yu International Conference on Computer Vision (ICCV), 2025 [Highlight] [paper] [code] |
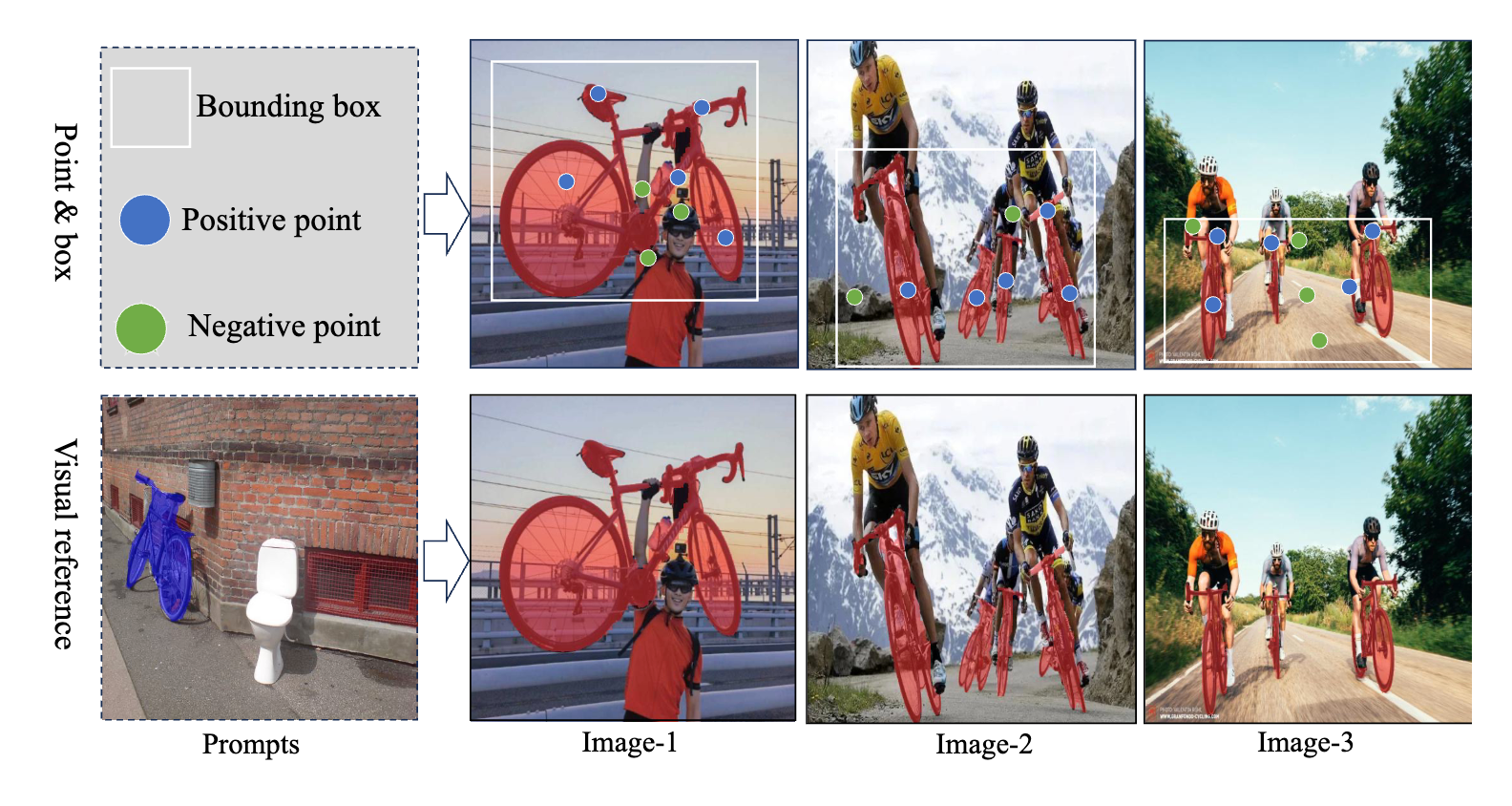
|
Yanpeng Sun, Jiahui Chen, Shan Zhang, Xinyu Zhang, Xiaofan Li, Qiang Chen, Gang Zhang, Errui Ding, Jingdong Wang, Zechao Li Computer Vision and Pattern Recognition Conference (CVPR), 2024 [paper] [code] |
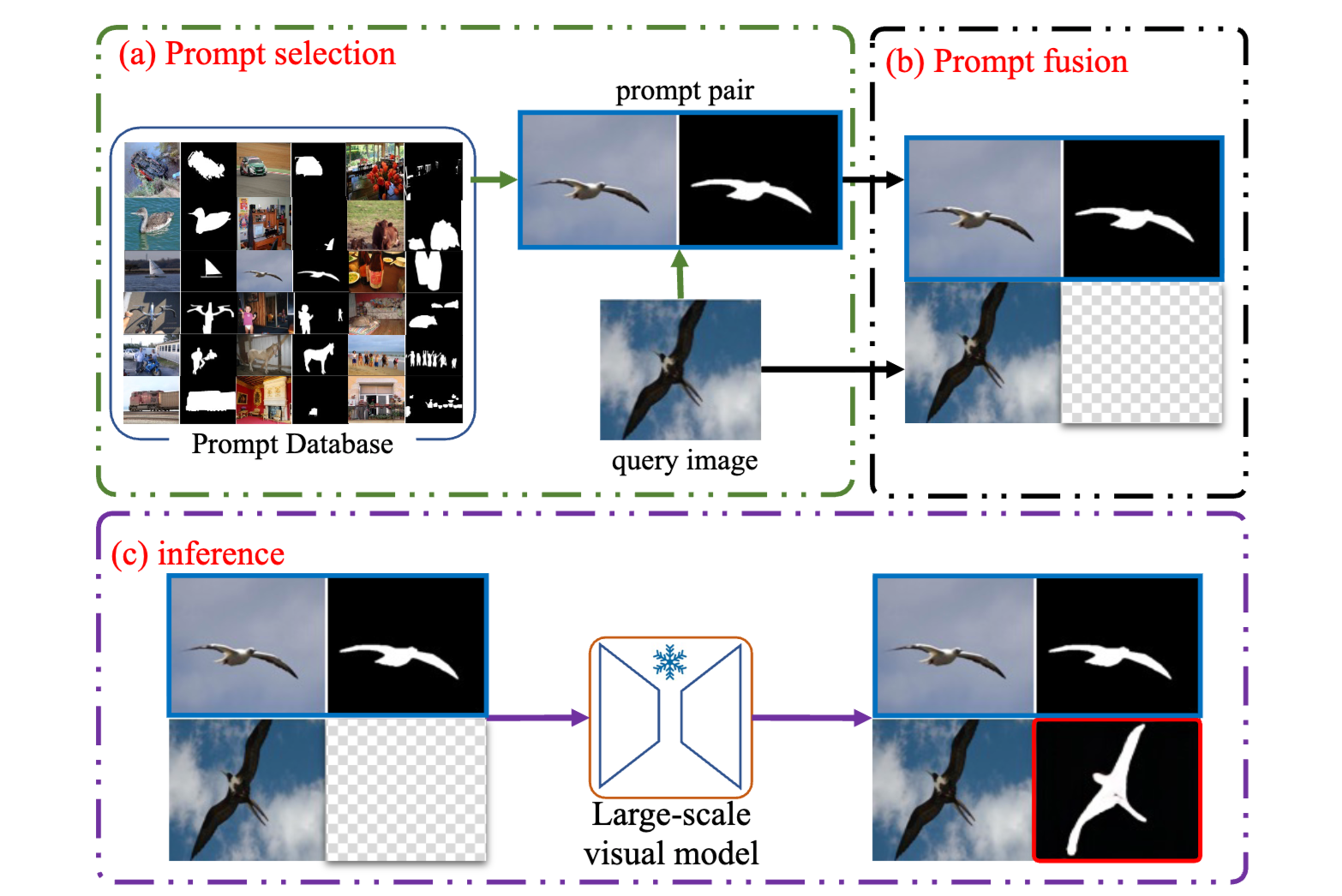
|
Yanpeng Sun, Qiang Chen, Xiaofan Li, Jian Wang, Jingdong Wang, Zechao Li IEEE Transactions on Image Processing (TIP), 2025 [paper] |
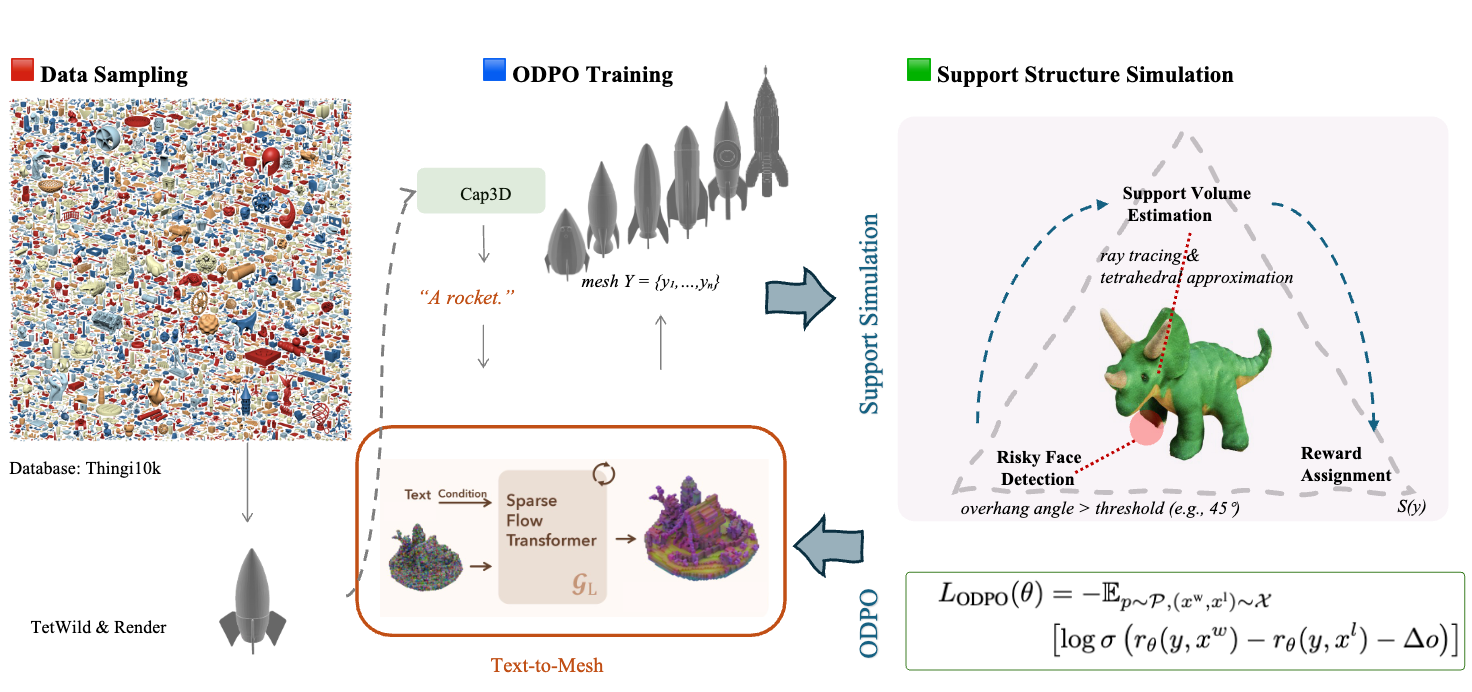
|
Chenming Wu*, Xiaofan Li*, Chengkai Dai (* equal contribution) IEEE Robotics and Automation Letters (RAL), 2026 [paper] |
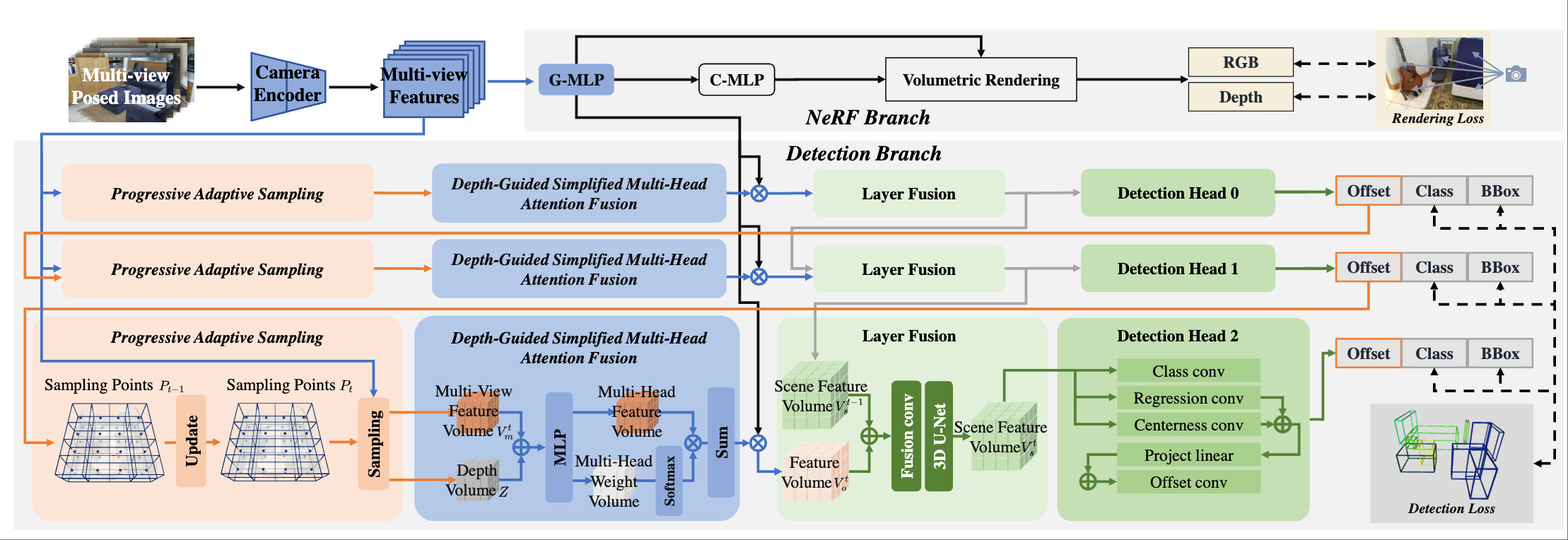
|
Chi Huang, Xinyang Li, Yansong Qu, Changli Wu, Xiaofan Li†, Shengchuan Zhang, Liujuan Cao† († equal advising) International Joint Conference on Artificial Intelligence (IJCAI), 2024 [paper] |

|
Huan Liu, Lingyu Xiao, Jiangjiang Liu, Xiaofan Li, Ze Feng, Sen Yang, Jingdong Wang arXiv preprint arXiv:2412.16418, 2024 [paper] |
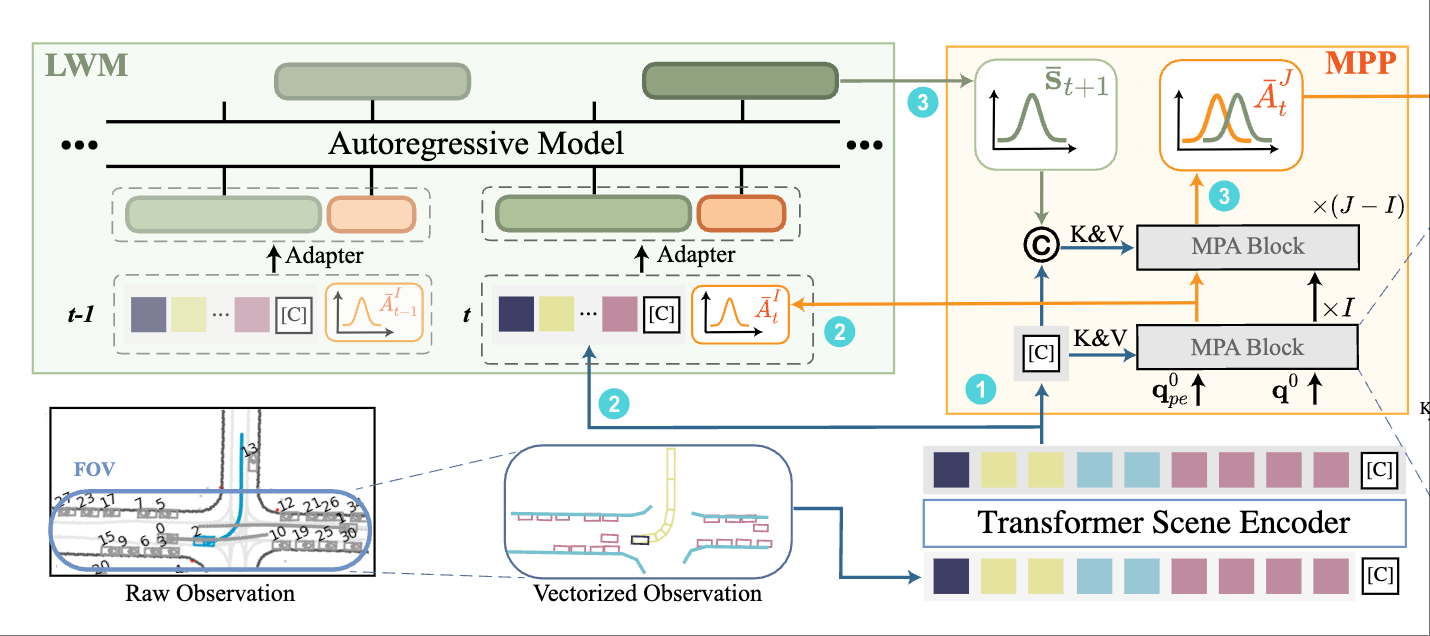
|
Lingyu Xiao, Jiang-Jiang Liu, Sen Yang, Xiaofan Li, Xiaoqing Ye, Wankou Yang, Jingdong Wang IEEE International Conference on Robotics and Automation (ICRA), 2025 [paper] [code] |
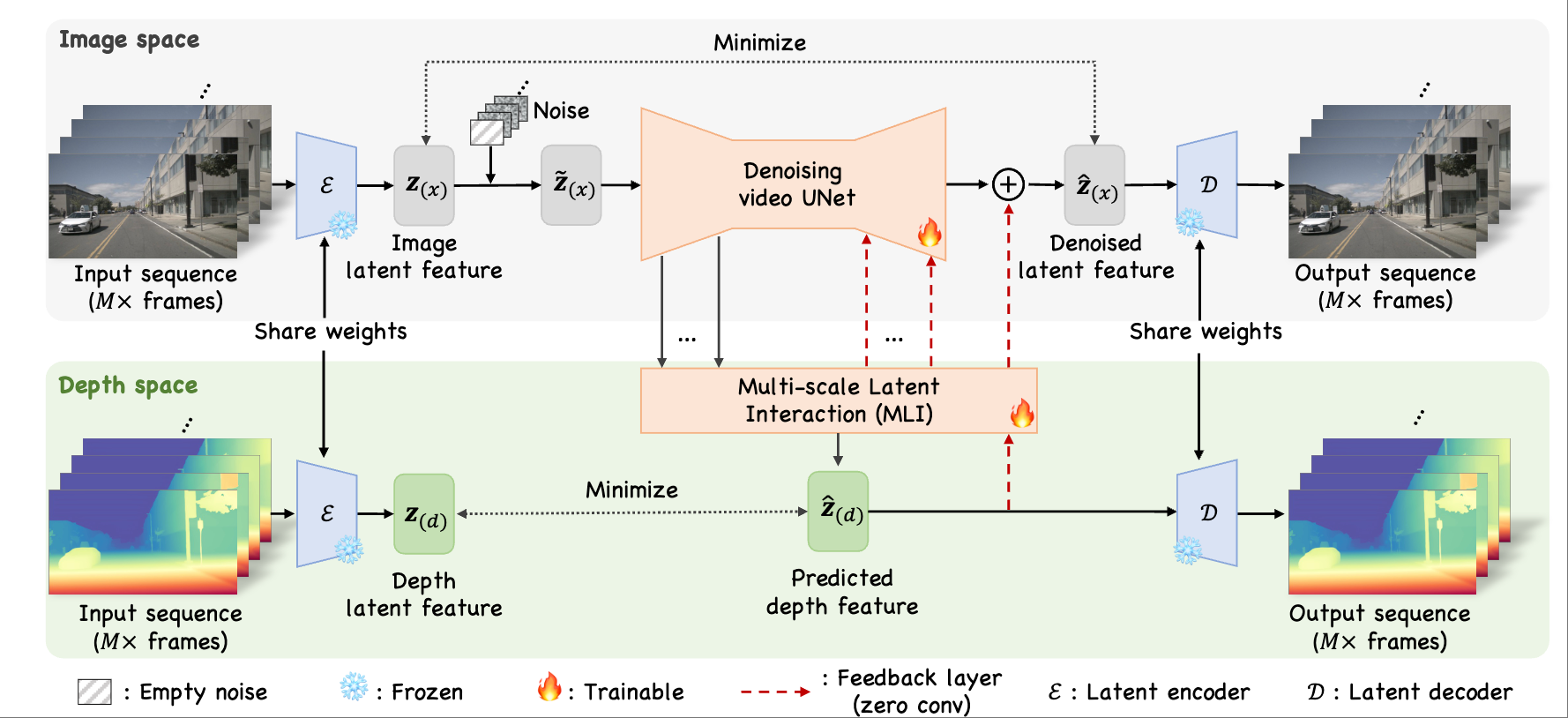
|
Dingkang Liang, Dingyuan Zhang, Xin Zhou, Sifan Tu, Tianrui Feng, Xiaofan Li, Yumeng Zhang, Mingyang Du, Xiao Tan, Xiang Bai IEEE International Conference on Robotics and Automation (ICRA), 2026 [paper] [code] |
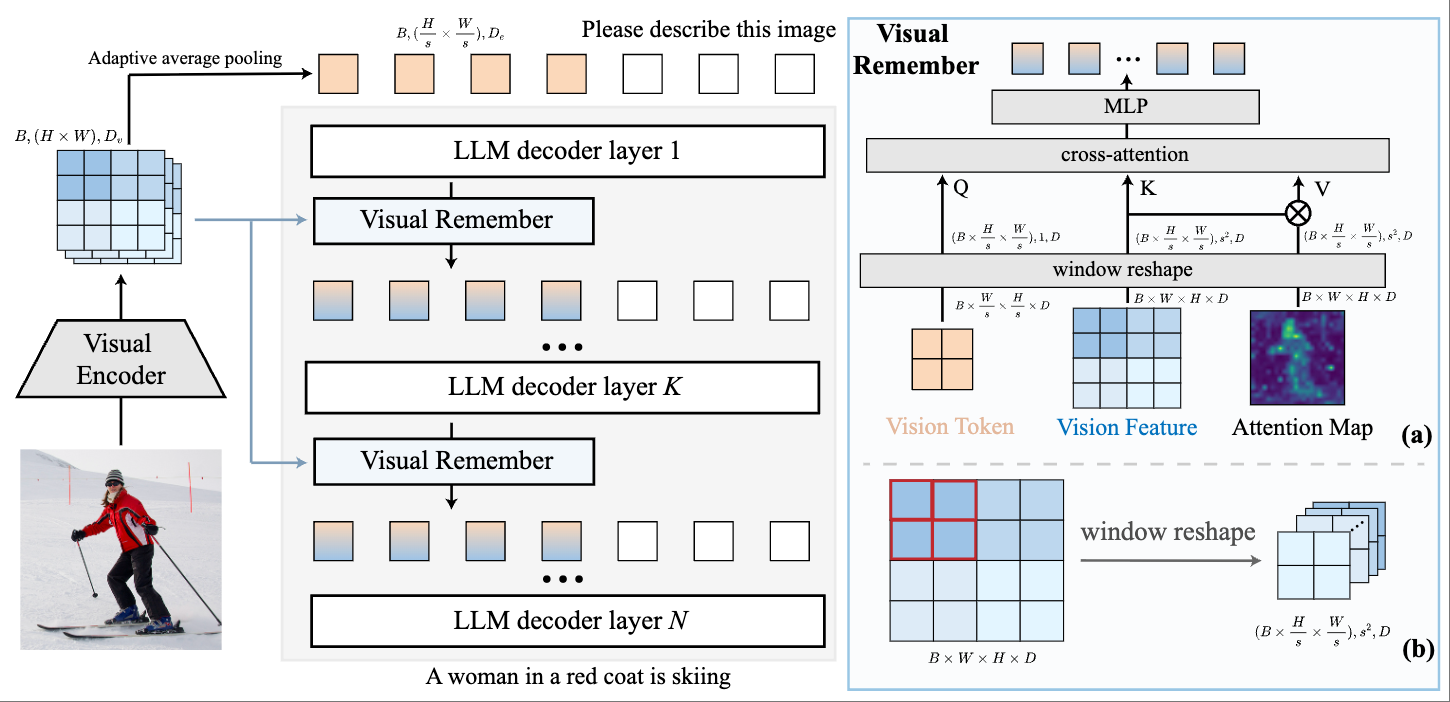
|
Ze Feng, Jiang-Jiang Liu, Sen Yang, Lingyu Xiao, Xiaofan Li, Wankou Yang, Jingdong Wang arXiv preprint arXiv:2506.03928, 2025 [paper] |

|
Yuzhi Chen, Qi Zeng, Muyang Zhang, Leilei Fan, Xiaofan Li†, Changwei Wang, Rongtao Xu, Yanchao Liu, MingMing Yu, Weiliang Meng († Corresponding author) SSRN (Elsevier), 2025 [paper] |
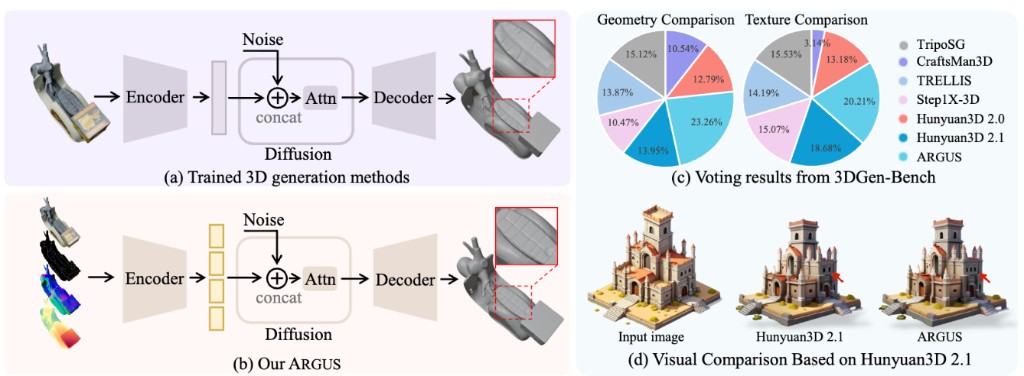
|
Mingyang Du, Dingkang Liang, Xin Zhou, Yumeng Zhang, Xiaofan Li, Kui Xia, Xiao Tan, Xiang Bai Under review |

|
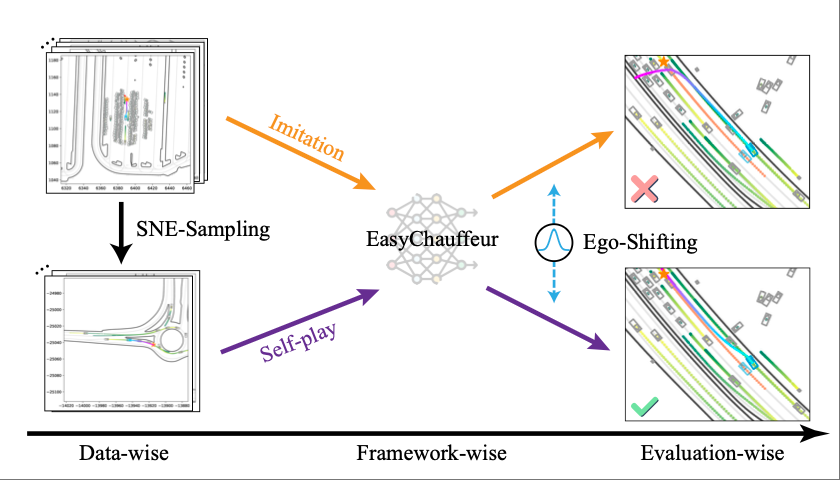
Xiaofan Li, Yuan Wang, Ji Wan, Jun Wang Under review |
|
Lingyu Xiao, Jiang-Jiang Liu, Xiaofan Li, Xiaoqing Ye, Wankou Yang Under review |

|
Xiao Luo, Xin Zhou, Mingyang Du, Tianrui Feng, Xiwu Chen, Xiaofan Li, Dingkang Liang Under review |
Talks & Presentations
|
Academic Service
- Conference Reviewer: NeurIPS, ICLR, ICML, CVPR, ICCV, ECCV, MM, ICRA, etc.
- Journal Reviewer: IJCV, Pattern Recognition, Neurocomputing
| © Xiaofan Li | Last update: June 2025 |